On this page you can find a step-by-step tutorial for creating a custom external script that is compatible with Manga Downloader.
Table of Contents
Introduction
To create a script you must choose which programming language to use. Yes, unfortunately you must know at least one programming language, no matter which one. Nowadays however, in addition to there being totally free learning guides in many resources on the web, there are AIs that help tremendously in writing and checking the code of any programming language, so even if you are starting from scratch know that it is no longer as difficult and challenging as it once was to learn to program in any language.
Fortunately, there is no limitation in which language can be used in our case, the important thing is that the final script be executable on the system (whether Windows or Linux or Mac). Keep in mind that your script will have to do essentially three things
- Download the HTML source of a web page (the one from the site you want to support)
- Parse the downloaded HTML code (so you can find the chapter list or the list of individual chapter pages depending on what you want to achieve)
- Create a JSON object to be printed then to the screen so that Manga Downloader can read and interpret it
That's all, it's just 3 simple steps. Many programming languages already have of their own internal or external libraries available that allow you to do these things (downloading, HTML parsing or JSON object creation) but nothing prohibits you from also using more archaic and manual methods (such as simple regex to parse the HTML code of your site, or manual creation via trivial strings of a JSON object) which however are obviously slightly more complicated and more easily prone to possible errors depending on your programming skills. However, I always recommend relying on libraries; they are much more secure and robust and save a great deal of time.
In this tutorial I will show you how to create an external script using 2 different languages that are also the most popular, namely Java and Python. Of course, I repeat, nothing prevents you from using any other language you want, mine are only guiding examples, you can do the equivalent with any language.
The website we will take as an example in this tutorial will be weebcentral.com.
1) Analysis of the website
The very first step you will need to take is to analyze the HTML code of the website you want to support. In fact, you need to figure out how to extrapolate from the HTML code of the website the data you are interested in (which are the chapter list and the page list of the individual chapters).
To see the source code of a web page you can use any web browser you want, but I recommend using Chrome because it has a useful feature called Inspect that allows you to check in one click the HTML code belonging to any part of the web page you are visiting.
So the first step is to open in your web browser the site you want to support and search for the title and chapter list of one of the manga it contains, for example we go to https://weebcentral.com/series/01J76XYDRMXQ5NEQNT4R3B0Z2N/Im-the-Grand-Dukes-Consort-Candidate-However-I-Believe-I-Can-Certainly-Surpass-It
At this point to check where the manga title is extracted on the page, let's select it and right-click after which we choose the item Inspect:
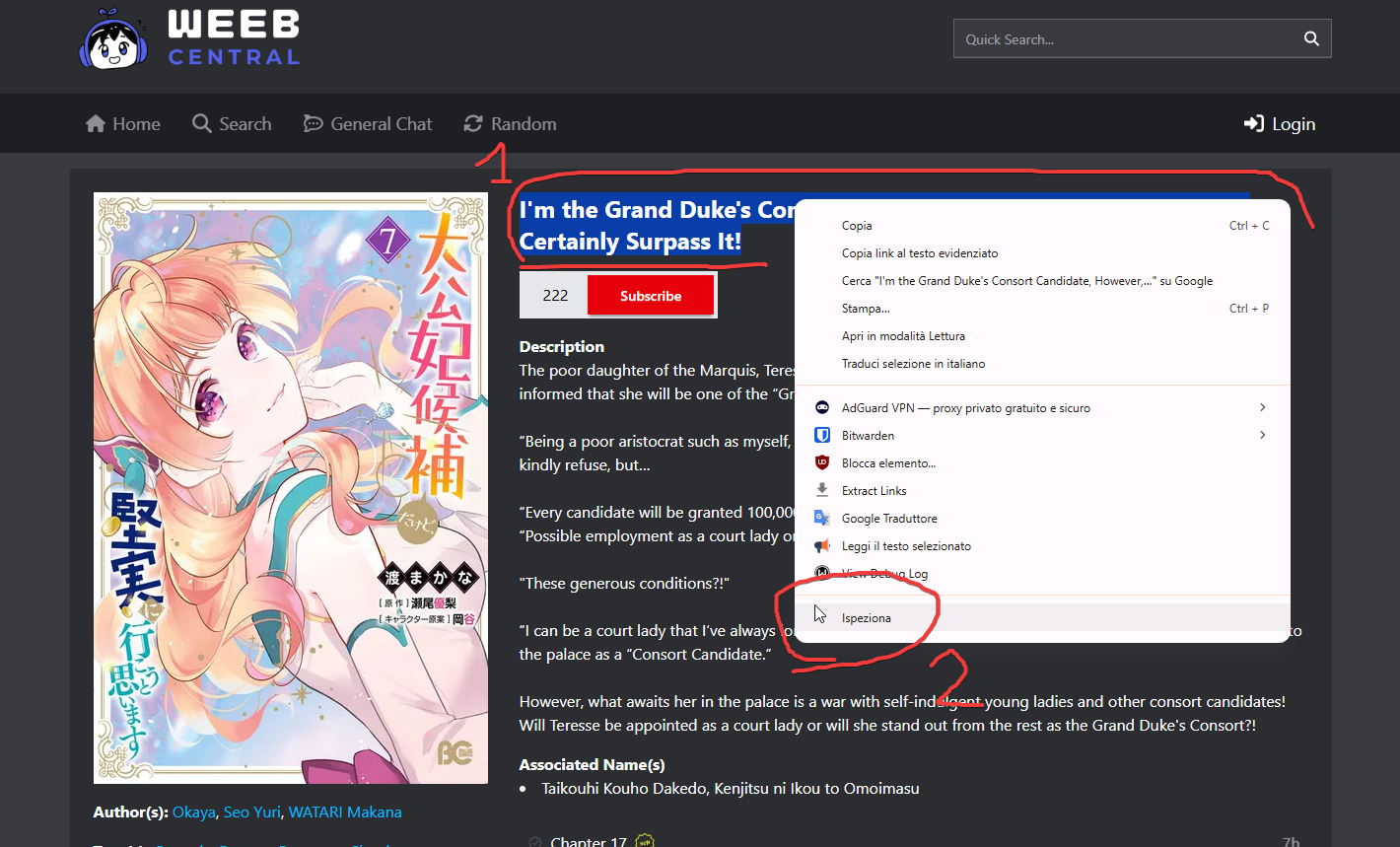
The Developer mode of the web browser will open and you will be shown the HTML code related to the part you are exploring:
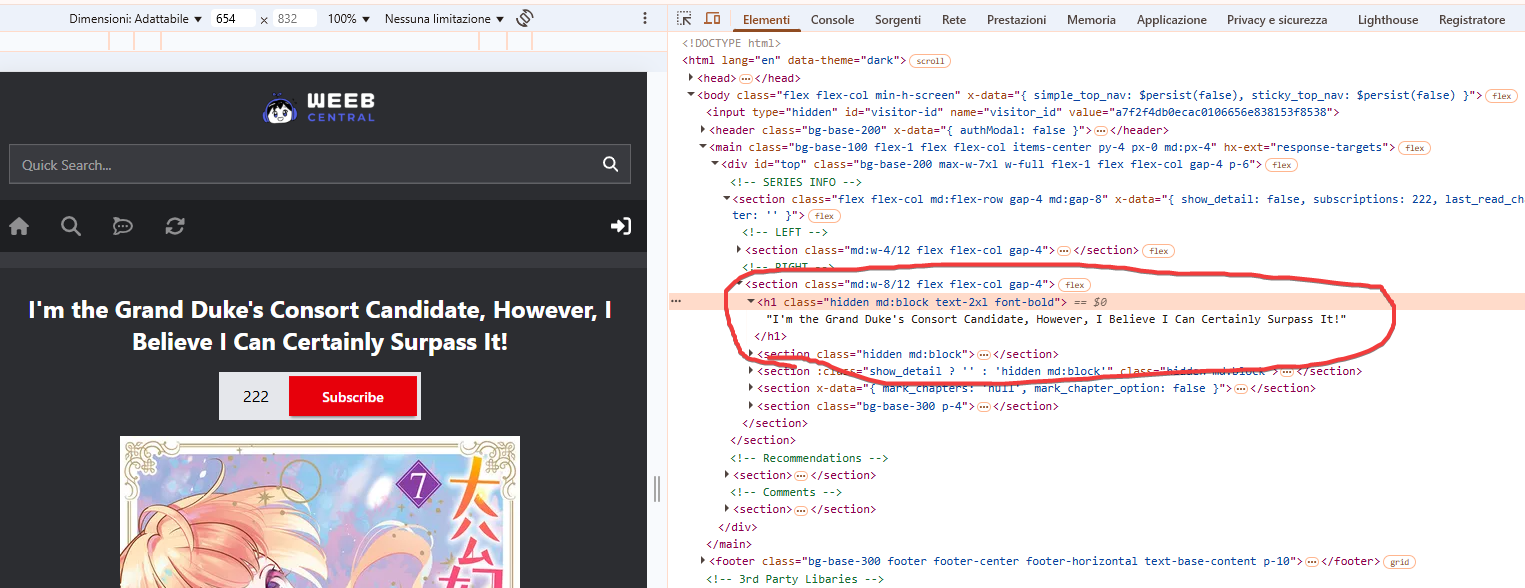
At this point we know that the manga title on the page is inside the first “h1” tag in the code. This will come in handy when we go to search for it with the script later.
Having found the title, now all we have to do is figure out how to pull up the chapter list. Still from the page we are on (no need to exit Developer mode) let's go to the chapter list on the preview page and right-click on it, always doing Inspect:
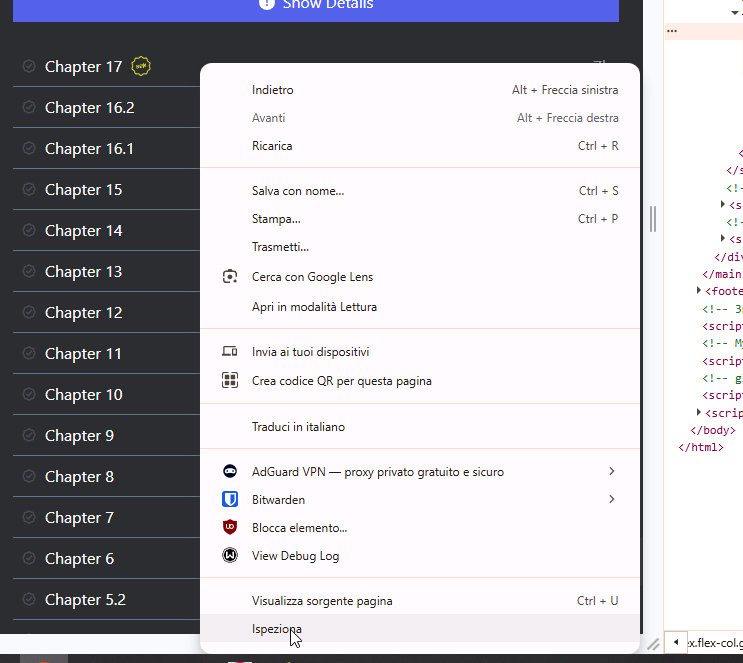
We will be redirected to the HTML code where the chapter we inspected appears. Moving the mouse over the HTML code will automatically select the relevant part on the web page preview, as visible from the image:
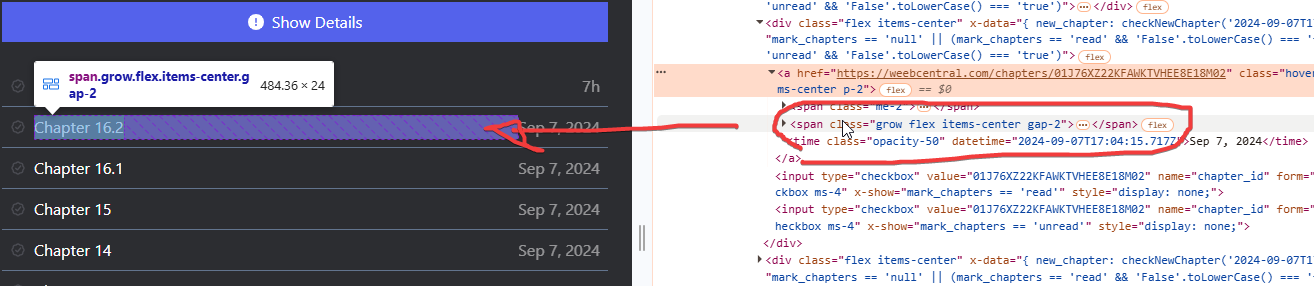
Here, however, we quickly notice one thing only one chapter is selected, namely the one we inspected. We, on the other hand, are interested in the whole chapter list, and so how to select it all? Just move upwards on the HTML code with the mouse and we will see that slowly different things will be selected within the web page preview. As soon as we notice that the whole chapter list is selected we will know that that is the block we will need to extract, in our example here it will be the “div” with id “chapters-list”:
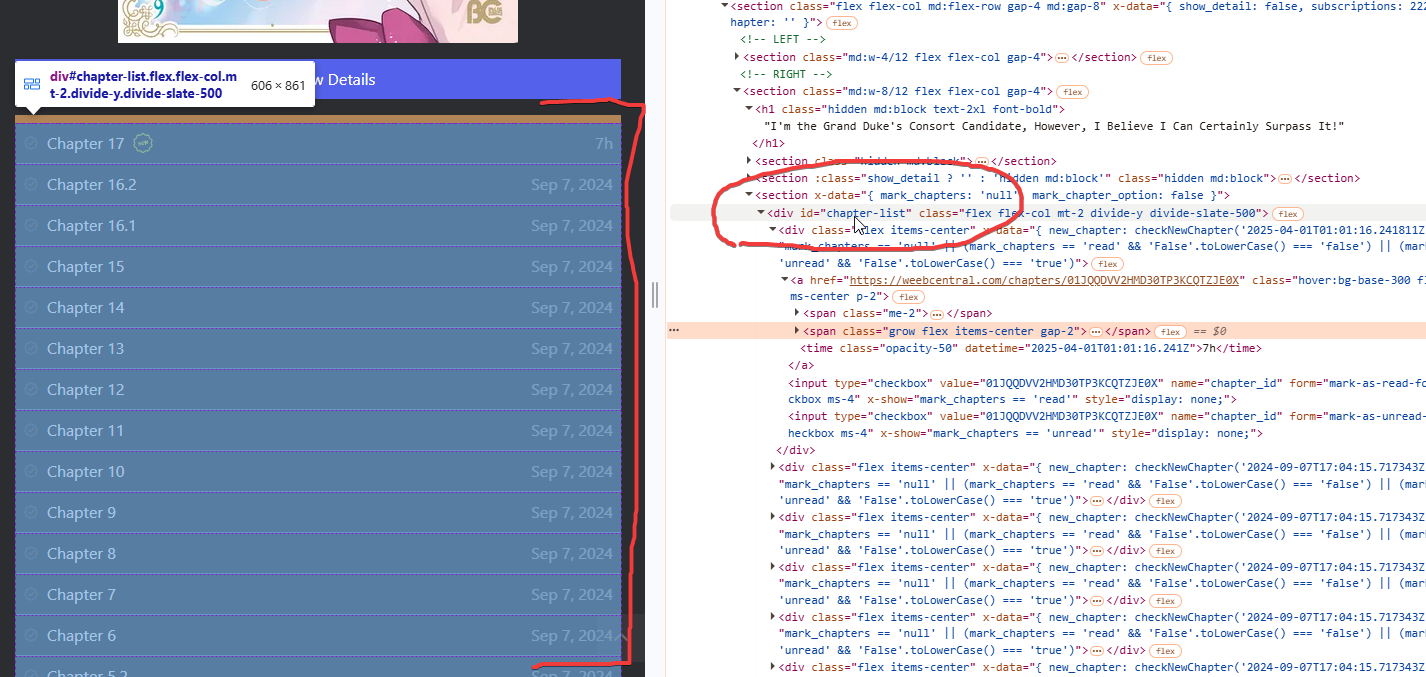
Once we have identified the chapter block to extract, we need to go to see how to extract the individual chapters from the list. Nothing could be simpler once we locate the block, because all we need to do is notice the similar repeating blocks of HTML code within it:
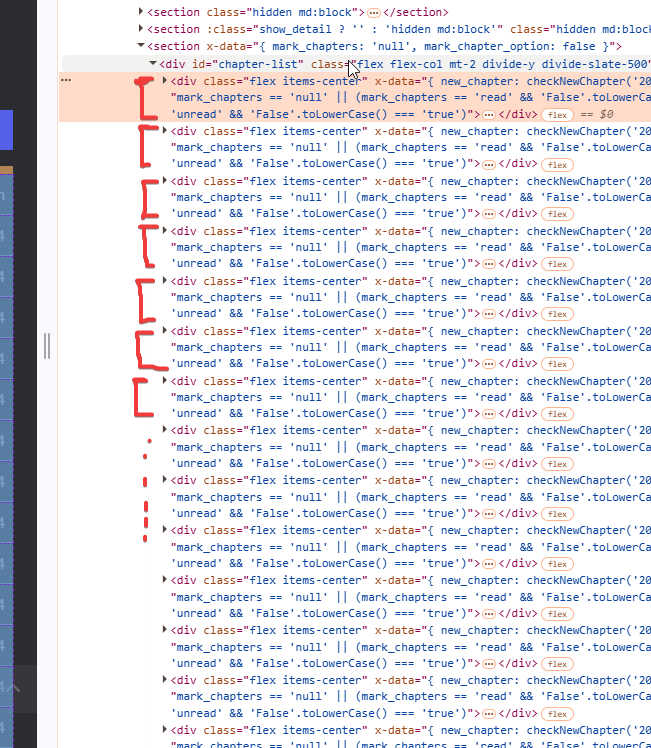
Each of these blocks corresponds to the individual chapter in the list. So now let's go and analyze these individual blocks to figure out how to extract the info about the individual chapter (usually just title and URL will suffice, but often other data such as translation group, uploader, release date, views are also present, all of which can be added if you want as they are supported by Manga Downloader). Now then we click on the little arrow to the left of the block to open it and analyze its contents:
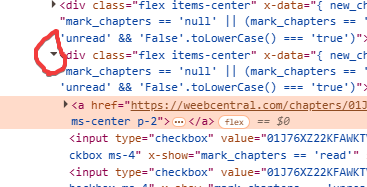
In this case we quickly realize that what we are interested in is all within the “a” tag block that we find inside it. Going to open that too always by clicking on the little arrow we will discover the various parts that make it up:
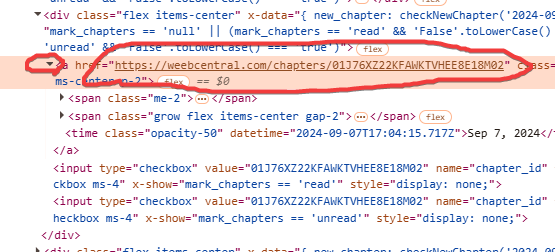
The first thing that immediately stands out to us is that the chapter URL is really the “href” attribute of this “a” tag. So we've already found one thing.
To find the title and other info, let us move the mouse over the various blocks contained within and see what is selected on the web page preview. In our case we will find that the chapter title is contained in the second “span” tag:
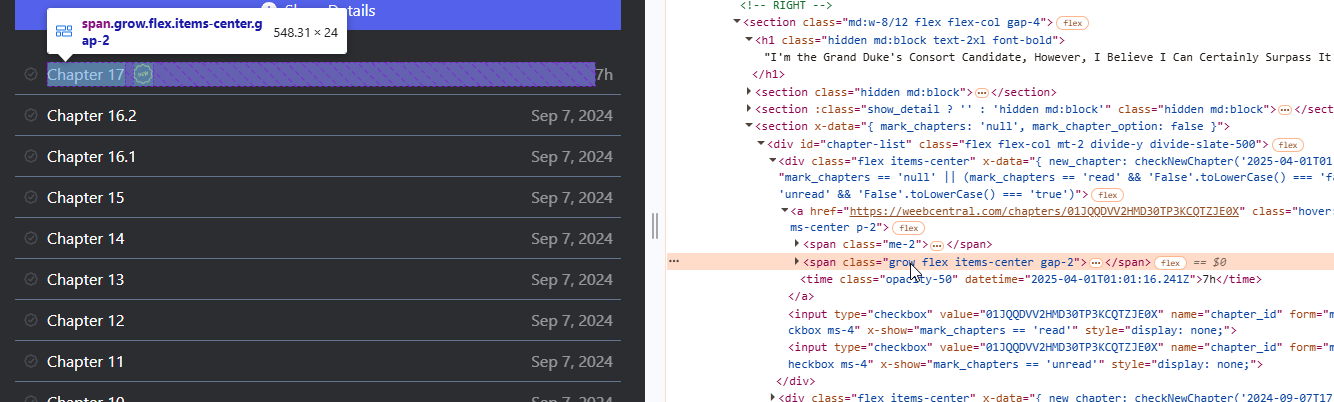
While an information about the release date of the chapter can be found on the tag “time”:
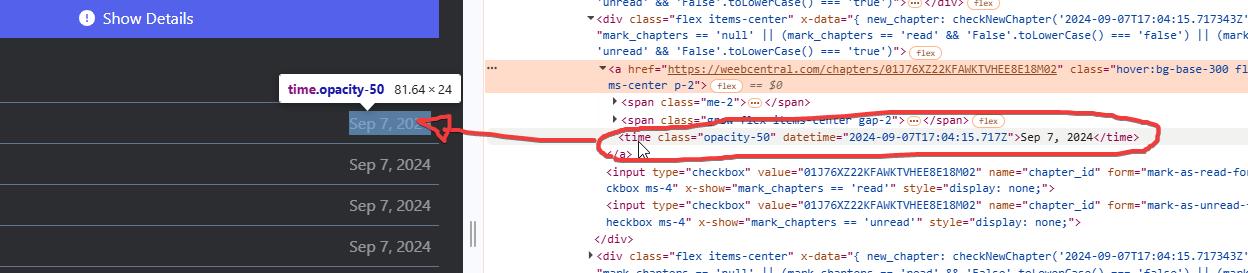
This is the only information that this website makes available about the individual chapters. So we can stop here, we have everything we need to extract the data we are interested in from the manga page, namely manga title, chapter list and for each chapter the title, URL and release date.
So now we can move on to trying to figure out how to extract the page list from a chapter. To do this we need to open any chapter from the site and once the pages are loaded go and see, using the Inspect button on any of the pages, at the HTML source level where they are placed:
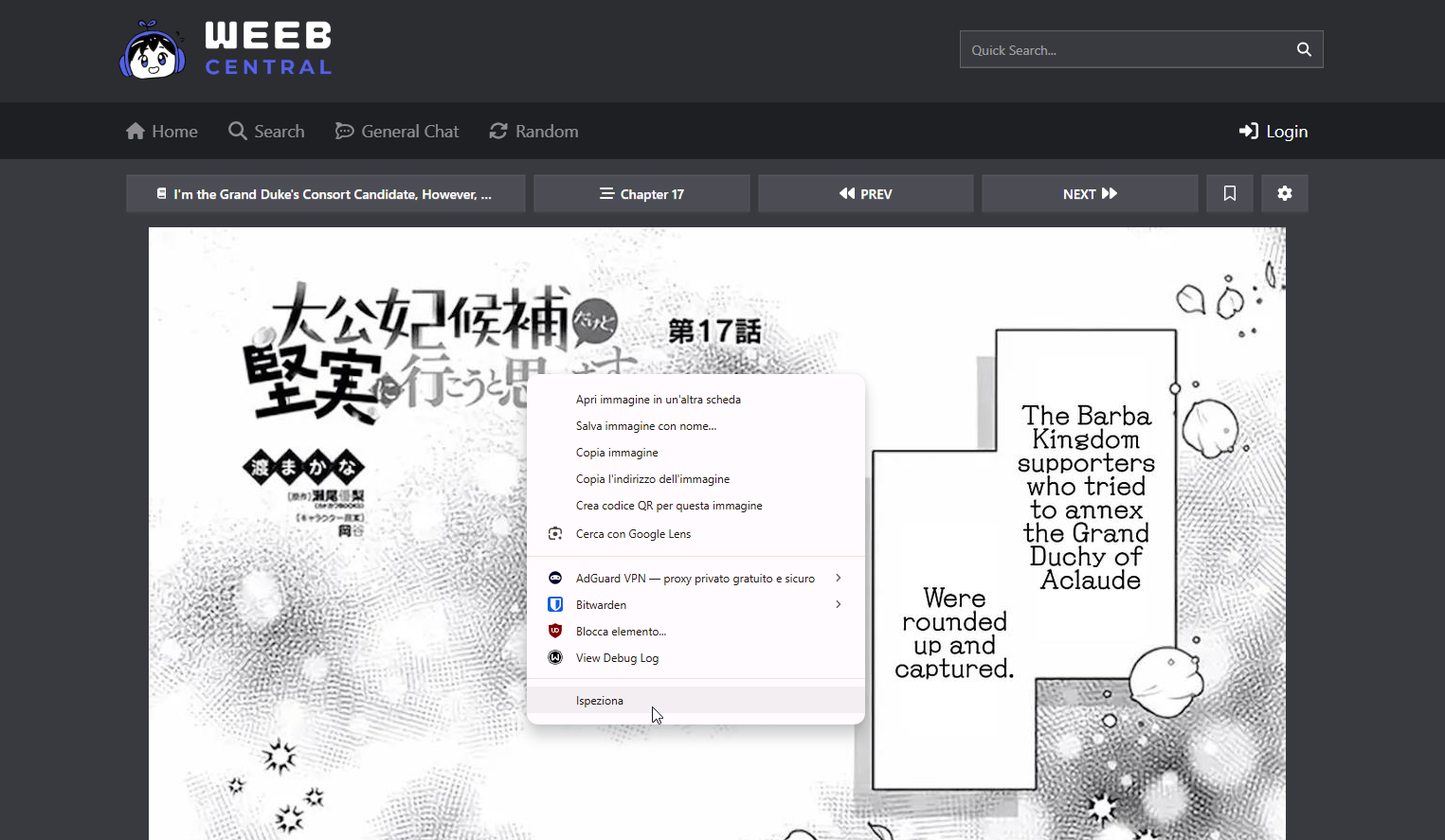
The usual Developer mode screen that you should be familiar with by now will open, and the corresponding HTML code for the image you clicked on Inspect will be displayed:
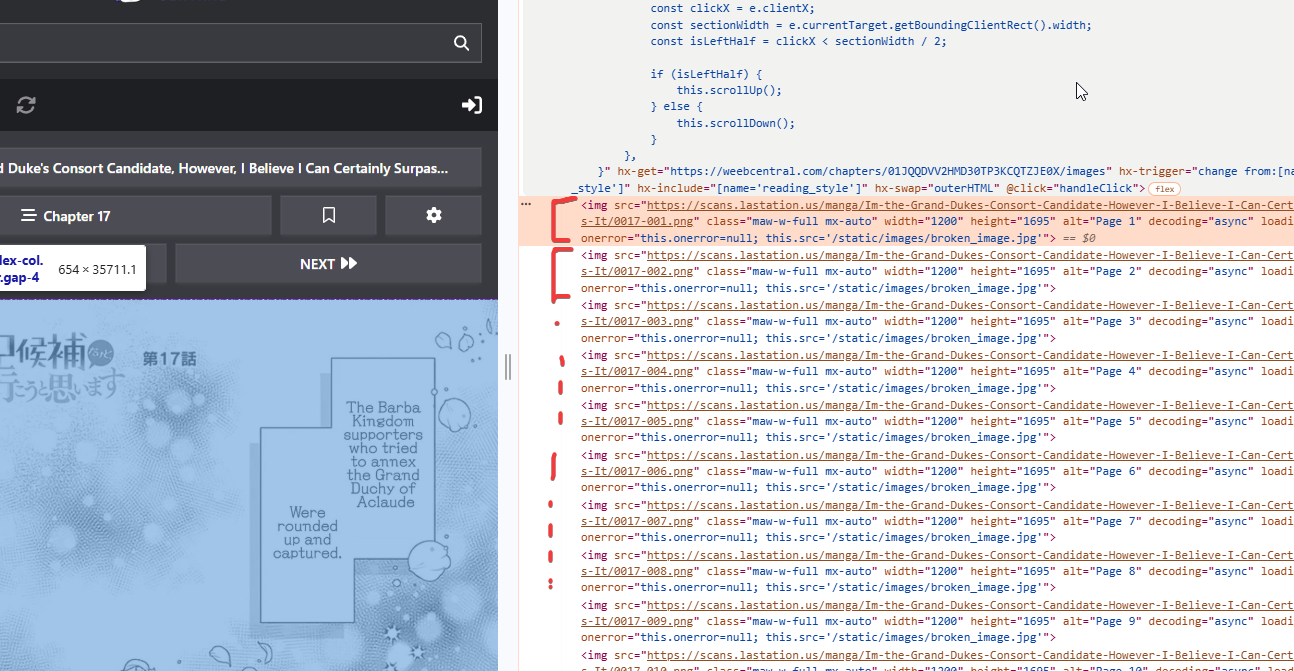
As we can see we got lucky because in this case they are simply images present, one after the other, within an “img” tag each. So we only need to extract the “src” attribute of each “img” tag present and we will have direct links to the images!
Important Note: what I have shown you is just a generic example of how to analyze a website to try to extract the info you need from it, unfortunately even though the method is general, obviously the specific tags are NOT valid for all websites! In fact, each website has its own HTML code that is almost certainly different from all others (unless they use generic frameworks), so you will unfortunately have to manually parse each website differently. I should also warn you that sometimes it is not so easy to figure out how to access the content because sites may obfuscate the source (making it difficult for a human to read), and in this case you will have to spend hours trying to reconstruct how it works. Similarly, websites often use Javascript to insert code dynamically within the HTML source code. This will cause that even if you see it within the web browser by inspecting it, then in reality those blocks of code will not be present in the HTML source code that you are going to download with your script! Getting around this problem will be even more complex because you will have to trace back to the Javascript code that the site is using, analyze and study that, and then engineer yourself into creating an equivalent method of accessing that content (e.g. by using an external Javascript interpreter perhaps, or by loading the code via an external web browser using special tools or libraries such as Selenium or similar ones). In short, extracting information from websites, especially official and advanced ones, can be quite a hard work to do and will not always be trivial. Obviously if you have the skills everything is possible, but for some websites I assure you that you will need well above average skills, so don't assume that you can easily support any website.
2) Creating the script
Once we've figured out how to extract the information we need from the website we want to support, it's time to move on to creating the actual scripts that will do the work. I leave below 2 examples in different programming languages (Java and Python) but, I repeat again, nothing would prohibit you from using other languages in the exact same way.
Using JAVA
As mentioned above, the script must essentially do 3 things, download the web page, extract the information from the HTML code, and print a JSON object on the screen that can then be interpreted by Manga Downloader. In JAVA all this can be done with 2 simple libraries jsoup and gson.
So here is the source code, commented step by step, of a JAVA script that can add support for weebcentral to Manga Downloader
// We import the necessary libraries // (of course they will have to be physically inserted into the classpath!) import com.google.gson.JsonArray; import com.google.gson.JsonObject; import org.jsoup.jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class Weebcentral { //The main is the first function that is started when you launch the script. public static void main(String[] args) { JsonObject output_json = new JsonObject(); // Let's create the JSON object to return if (args.length != 2) { // We check that the arguments are correct, otherwise we give an error message. output_json.addProperty("error", "Invalid arguments count."); } else { if (args[1].equalsIgnoreCase("CHAPTERS")) { // If the second argument is CHAPTERS then we start the function to acquire the chapter list GetChapters(args[0]); return; } else if (args[1].equalsIgnoreCase("PAGES")) { // If the second argument is PAGES then we start the function to acquire the page list GetPages(args[0]); return; } else { // If the second argument is wrong we show an error message. output_json.addProperty("error", "Unknown second argument (it can be only CHAPTERS or PAGES)."); } } System.out.println(output_json.toString()); // Let's print any error messages on the screen } // GetChapters takes the URL of a manga as an argument and prints title and chapter list information on the screen private static void GetChapters(String u) { JsonObject output_json = new JsonObject(); // Let's create the JSON object to be printed on the screen Document doc; try { doc = Jsoup.connect(u).timeout(10*1000).get(); // We connect to the website and acquire its HTML source Elements content = doc.getElementsByTag("h1"); // We extract the first element with tag h1 if (content.isEmpty()) { output_json.addProperty("manga", "ERROR"); // If the tag is not found then we show an error as the manga title } else { output_json.addProperty("manga", content.first().ownText().trim()); // If the tag is found we add the manga title to the JSON object } JsonArray out_chapters = new JsonArray(); // We create the JSON array that will contain the various chapters Element div = doc.getElementById("chapter-list"); // We extract the element with ID chapter-list Elements as = div.getElementsByTag("a"); We extrapolate all elements with tag a from the element extracted above for (Element a : as) { // For each element with tag a present JsonObject out_chapter = new JsonObject(); // We create the JSON object that will contain the info of the individual chapter out_chapter.addProperty("title", a.select(span[class='']).text().trim()); // We extract the chapter title and add it to the JSON object out_chapter.addProperty("url", a.attr("href")); // We extract the URL of the chapter and add to the JSON object out_chapter.addProperty("date", a.getElementsByTag("time").attr("datetime").trim()); // Let's extrapolate the chapter release date and add it to the JSON object out_chapter.addProperty("language", "English"); // We manually set the language of the website and add to the JSON object // Since we have no information about it we manually set the last missing fields to an empty string and add them to the JSON object out_chapter.addProperty("group", ""); out_chapter.addProperty("uploader", ""); out_chapter.addProperty("views", ""); out_chapters.add(out_chapter); // Finally, we add the JSON object we just filled with information to the previously created array } output_json.add(chapters, out_chapters); // Let's add the now-filled array of chapters to the JSON object to be printed on the screen } catch (Exception e) { output_json.addProperty("error", "Error while getting chapters list (" + e.getMessage() + ")"); // In case of any errors we add an error message to the JSON object to be printed on the screen } System.out.println(output_json.toString()); // Let's print out the final JSON object on the screen that Manga Downloader will go to read } // GetPages takes as an argument the URL of a chapter (obtained from the GetChapters() function) and prints title and chapter list information on the screen private static void GetPages(String u) { JsonObject output_json = new JsonObject(); // Let's create the JSON object to be printed on the screen output_json.addProperty("user-agent", ""); // Since we don't need it we set the user-agent field to an empty string output_json.add("cookies",new JsonArray()); // Since we don't need cookies to access the website, we set the cookie field to an empty JSON array try { /* We download the HTML source from the website Note in this case I am going to add some parameters to the URL of the chapter that will make me show all the pages, since otherwise the site will Would only load 1 of page at a time. I discovered these parameters simply by browsing the site and checking the URL bar on the web browser, obviously not needed all the time but is specific to this site. */ Document doc = Jsoup.connect(u + "imagesis_prev=False&reading_style=long_strip").timeout(10 * 1000).get(); String link; JsonArray out_pages = new JsonArray(); // We create the JSON array that will contain the various links to the pages Elements imgs = doc.getElementsByTag("img"); // Let's extrapolate the elements with tag img for (int i = 0; i imgs.size(); i++) { // For each element with tag img link = imgs.get(i).attr("src").trim(); // Let's extrapolate the direct link to the image file out_pages.add(link); // Let's add the newly extracted link to the pages array } output_json.add("pages", out_pages); // We add the array with the pages to the final JSON object to be printed to the screen } catch (Exception e) { output_json.addProperty("error", "Error while getting pages list (" + e.getMessage() + ")"); // In case of any errors we add an error message to the JSON object to be printed on the screen } System.out.println(output_json.toString()); // Let's print out the final JSON object on the screen that Manga Downloader will go to read } }
Using Python
To give you proof that you don't have to know JAVA to create scripts, I'll leave you with a script written this time in Python and that does exactly the same things that the JAVA script you saw above did (there's no point in me commenting on it again so much as you can understand easily the equivalent steps). This time the libraries Python will use are requests to download web pages, BeautifulSoup to parse HTML code, and json to create JSON objects.
import sys import requests import json from bs4 import BeautifulSoup def get_chapters(url): output_json = {} try: response = requests.get(url, timeout=10) response.raise_for_status() soup = BeautifulSoup(response.text, 'html.parser') title_element = soup.find('h1') if title_element: output_json["manga"] = title_element.text.strip() else: output_json["manga"] = "ERROR" chapters = [] chapter_list_div = soup.find(id="chapter-list") if chapter_list_div: for a in chapter_list_div.find_all('a'): chapter_info = { "title": a.find('span', class_='').text.strip(), "url": a.get('href'), "date": a.find('time').get('datetime').strip(), "language": "English", "group": "", "uploader": "", "views": "" } chapters.append(chapter_info) output_json["chapters"] = chapters except Exception as e: output_json["error"] = f"Error while getting chapters list ({str(e)})" print(json.dumps(output_json, indent=4)) def get_pages(url): output_json = { "user-agent": "", "cookies": [] } try: response = requests.get(f"{url}/images?is_prev=False&reading_style=long_strip", timeout=10) response.raise_for_status() soup = BeautifulSoup(response.text, 'html.parser') pages = [] for img in soup.find_all('img'): src = img.get('src').strip() pages.append(src) output_json["pages"] = pages except Exception as e: output_json["error"] = f"Error while getting pages list ({str(e)})" print(json.dumps(output_json, indent=4)) def main(): if len(sys.argv) != 3: print(json.dumps({"error": "Invalid arguments count."}, indent=4)) return url, mode = sys.argv[1], sys.argv[2].upper() if mode == "CHAPTERS": get_chapters(url) elif mode == "PAGES": get_pages(url) else: print(json.dumps({"error": "Unknown second argument (it can be only CHAPTERS or PAGES)."}, indent=4)) if __name__ == "__main__": main()
3) Configuration of Manga Downloader
Now that you have created your script you need to set up Manga Downloader for it to use it correctly. Since the scripts in these examples do not involve the creation of an executable (an EXE under Windows to be clear) we will have to manually create launchers for the script, nothing complicated. We create a simple TXT text file and inside it we write the complete command to launch the script we have chosen depending on which operating system we are using. For example, to launch the JAVA script on Windows it will be enough to write inside the text file:
@echo off java -jar script.jar %*
where instead of script.jar the name you will have given your script after compilation should be inserted. The part with “echo off” is just to prevent anything else from being printed to the screen besides the program return JSON output (so that Manga Downloader cannot interpret what is printed in correct JSON) while the part with “%*” is to make sure that the arguments (URL and keyword) that Manga Downloader passes to the executable when it calls it are passed to the script that you programmed.
Now if you want to use this launcher under Windows rename the .txt text file with a .bat extension, so that it becomes executable and changes icon as in the image:

If you want to use it under Linux or Mac instead, you will have to edit the text file like this
#!/bin/bash java -jar script.jar "$@"
where instead of script.jar you should always enter the name you will have given your script.
Now you will need to rename this text file to .sh format and give it execution permissions by giving this command from a terminal:
chmod +x script.sh
obviously with the terminal you must have already moved to the folder where the newly created launcher is located or it will not find the file.
Note if your script was the one in Python for example, then instead of
@echo off java -jar script.jar %*
you should write
@echo off python script.py %*
basically what changes is just the command to launch the script, this happens with every language you are using but I think you already know that.
Having created the executable, make sure it is placed inside the same folder where the main script (in this case the .jar file) is located. To make sure that everything works properly, even before using it with Manga Downloader, we can try to start the script from the terminal by giving it as arguments the URL of the manga we want to download and the keyword CHAPTERS, so that we can check that the list of chapters is correctly printed on the screen as shown in the image:
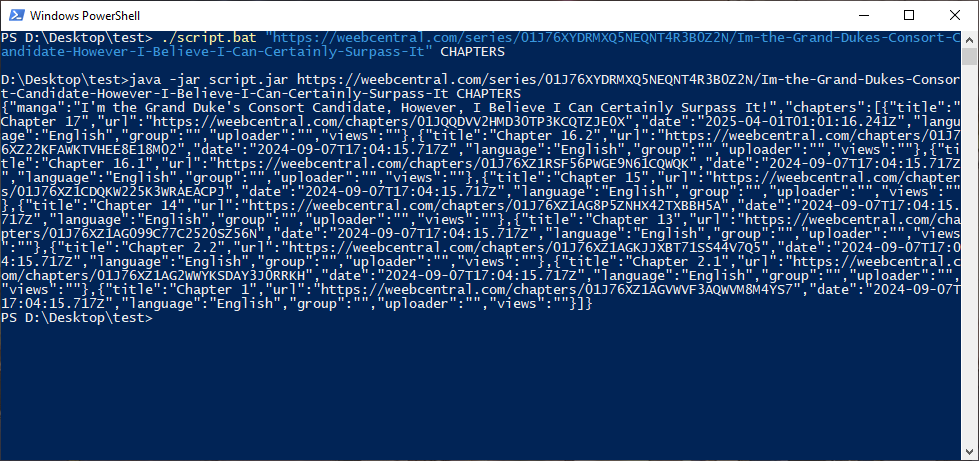
If we want, we can test the pages as well, simply by changing the parameters with the URL of one of the chapters and the keyword PAGES:
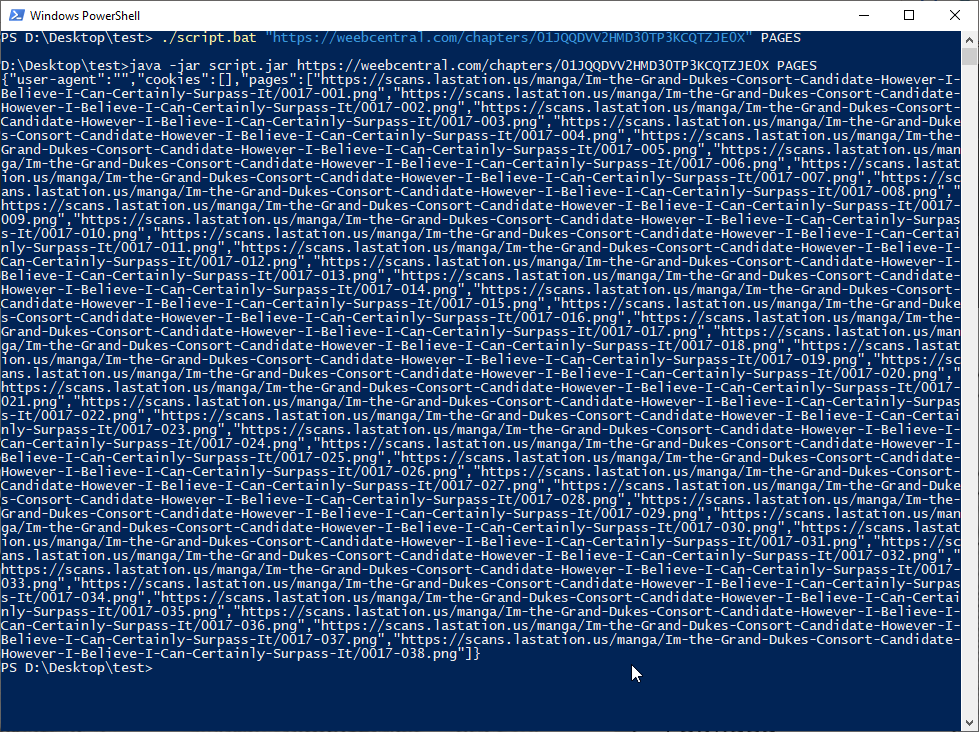
Now that we are sure that our script is working properly, let's move on to configuring Manga Downloader. Start the program and click on the Edit menu then choose the item External Scripts:
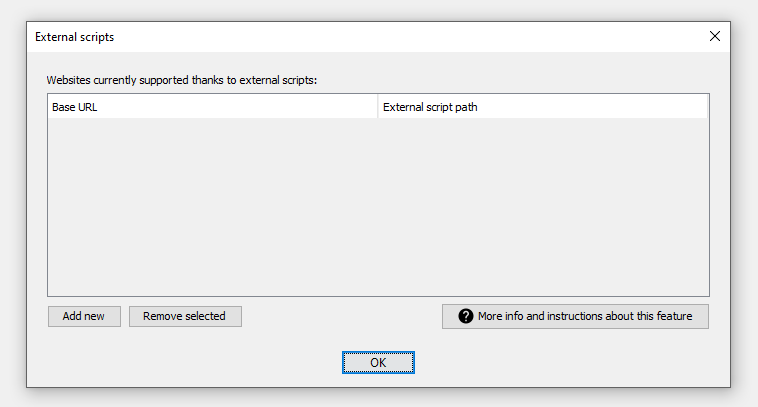
On the screen that will appear click on the Add button and you will be asked to enter the domain of the website you want to support with your script, in our example therefore we will enter weebcentral.com
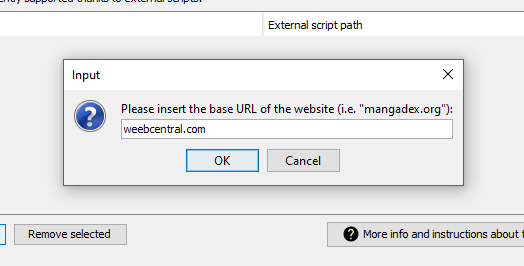
You will now be asked to select the executable file of your script. Be careful here to select the launcher (in BAT or SH format that you created earlier) and not the script directly. Once completed you will have something like this:
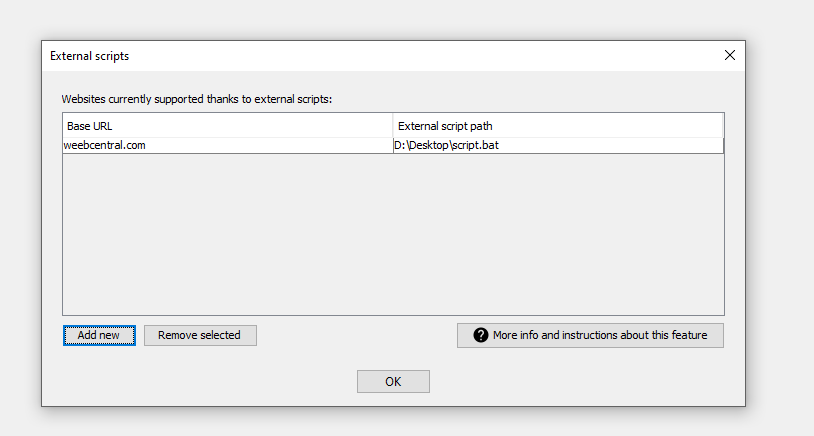
At this you give the ok to save everything and you are ready to use your script!
Open the new manga input screen from the program and enter the URL of the manga you want to download, making sure to select the External Script as Generic Framework box below it:
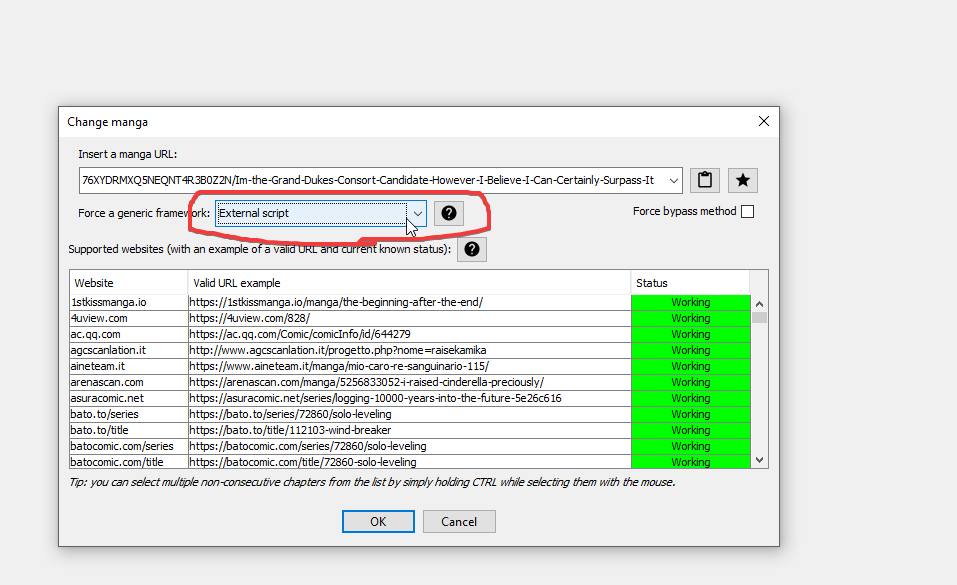
Confirm and if your script is correct Manga Downloader will load the chapter data inside the program by using your script:
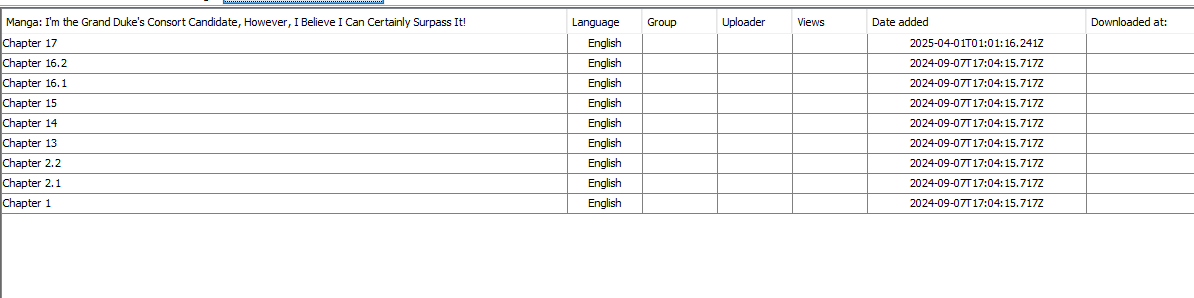
And it will allow you to download chapters without errors:
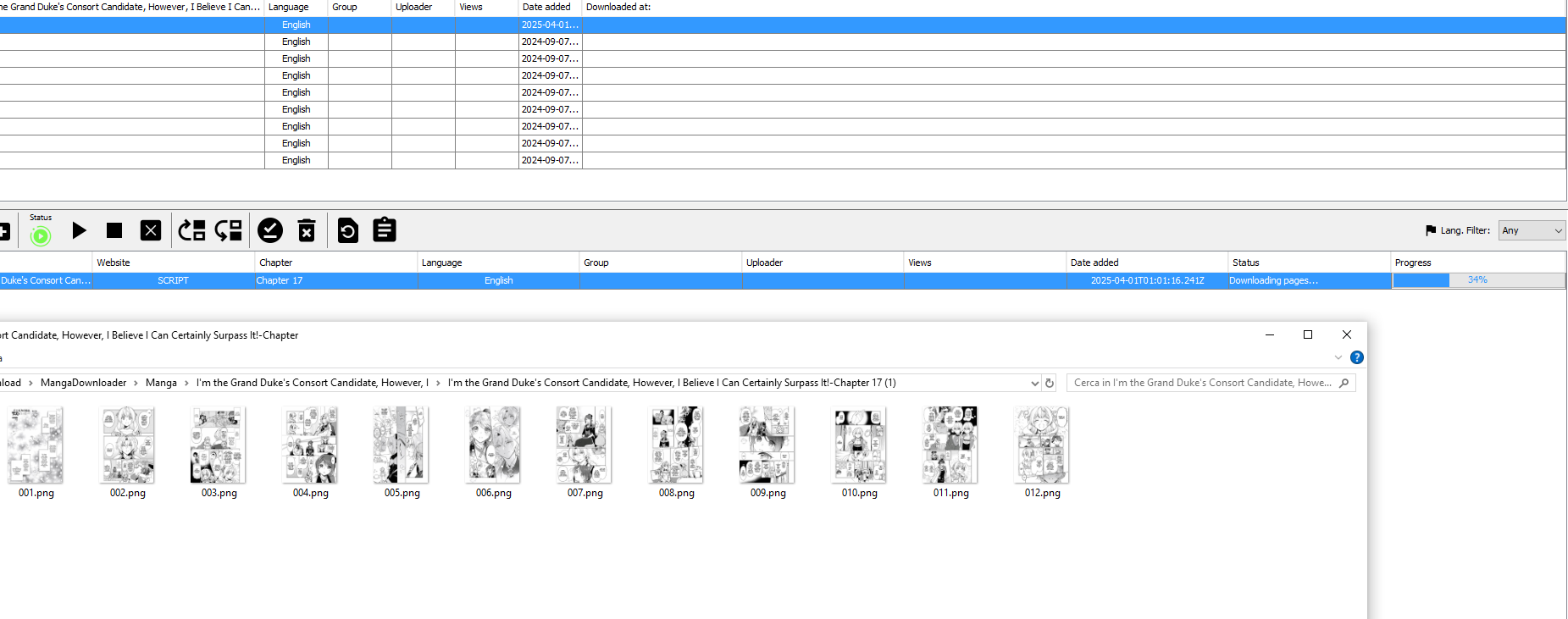
And we are done! Now you can use the external script for all the manga on that website, and if the website changes in the future you can just update your script without even having to wait for an official Manga Downloader update anymore.