In questa pagina potete trovare un tutorial passo per per creare uno script personalizzato esterno che sia compatibile con Manga Downloader.
Indice
Introduzione
Per creare uno script dovete scegliere quale linguaggio di programmazione usare. Si, purtroppo dovete conoscere almeno un linguaggio di programmazione, non importa quale. Al giorno d'oggi comunque, oltre ad essere presenti guide per l'apprendimento totalmente gratuite in molte risorse sul web, ci sono le IA che aiutano enormemente nella stesura e nel controllo del codice di qualsiasi linguaggio di programmazione, quindi anche se partite da zero sappiate che non è più così difficile e impegnativo com'era una volta imparare a programmare in un qualsiasi linguaggio.
Fortunatamente non c'è alcuna limitazione in quale linguaggio si possa usare nel nostro caso, l'importante è che lo script finale sia eseguibile sul sistema (sia esso Windows o Linux o Mac). Tenete presente che il vostro script dovrà fare essenzialmente tre cose:
- Scaricare il sorgente HTML di una pagina web (quella del sito che vuoi supportare)
- Analizzare il codice HTML scaricato (in modo da trovare l'elenco dei capitoli o quello delle pagine del singolo capitolo a seconda di cosa vuoi ottenere)
- Creare un oggetto JSON da stampare poi a schermo in modo che Manga Downloader possa leggerlo e interpretarlo
Tutto qui, sono solo 3 semplici passaggi. Molti linguaggi di programmazione hanno già di loro a disposizione librerie interne o esterne che permettono di fare queste cose (download, analisi HTML o creazione di oggetti JSON) ma nulla vi vieta di utilizzare anche metodi più arcaici e manuali (come ad esempio semplice regex per analizzare il codice HTML del sito, o la creazione manuale tramite banali stringhe di un oggetto JSON) che però ovviamente sono leggermente più complicati e più facilmente soggetti a possibili errori a seconda della propria abilità di programmazione. Io comunque consiglio sempre di affidarsi a delle librerie, sono molto più sicure e solide e fanno risparmiare moltissimo tempo.
In questo tutorial io vi illustrerò come creare uno script esterno usando 2 linguaggi diversi che sono anche i più diffusi, ossia Java e Python. Ovviamente, ripeto, nulla vi vieta di usare qualsiasi altro linguaggio che desideriate, i miei sono soltanto esempi guida, si può fare l'equivalente con qualsiasi linguaggio.
Il sito web che prenderemo ad esempio in questo tutorial sarà weebcentral.com.
1) Analisi del sito web
Il primissimo passo che dovrete fare è analizzare il codice HTML del sito web che volete supportare. Infatti dovete capire come fare per estrapolare dal codice HTML del sito web i dati che vi interessano (che sono la lista dei capitoli e quella delle pagine dei singoli capitoli).
Per vedere il codice sorgente di una pagina web potete usare qualsiasi browser web vogliate, ma io vi consiglio di usare Chrome perché ha una utile funzione denominata “Ispeziona” che permette di controllare in un click il codice HTML appartenente ad una qualsiasi parte della pagina web che state visitando.
Quindi il primo step è aprire nel vostro browser web il sito che volete supportare e cercare il titolo e la lista capitoli di uno dei manga che contiene, ad esempio andiamo su https://weebcentral.com/series/01J76XYDRMXQ5NEQNT4R3B0Z2N/Im-the-Grand-Dukes-Consort-Candidate-However-I-Believe-I-Can-Certainly-Surpass-It
A questo punto per controllare dove si estrae il titolo del manga nella pagina, selezioniamolo e clicchiamo col tasto destro dopodiché scegliamo la voce Ispeziona:
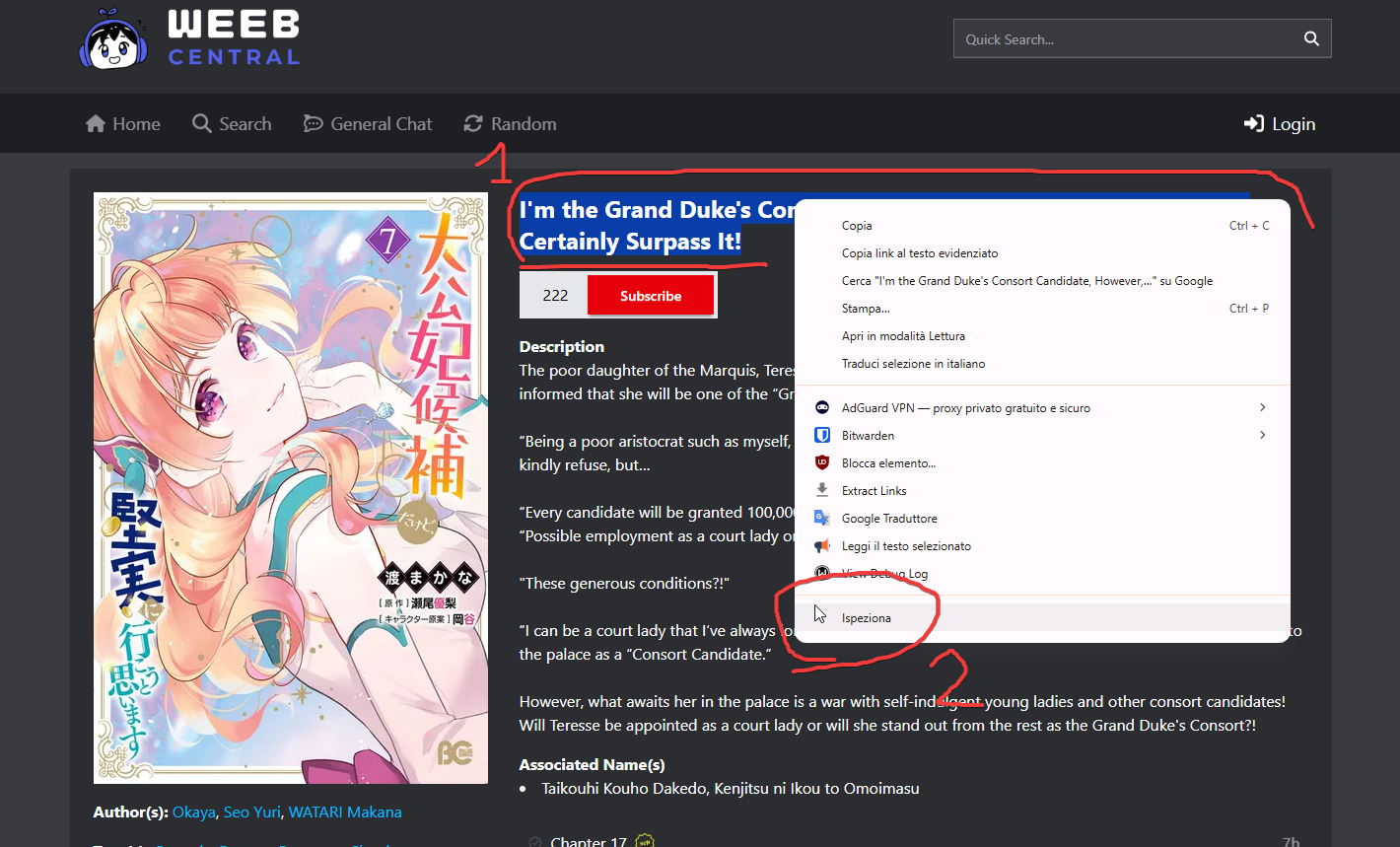
Si aprirà la modalità Sviluppatore del browser web e vi verrà mostrato il codice HTML relativo alla parte che state esplorando:
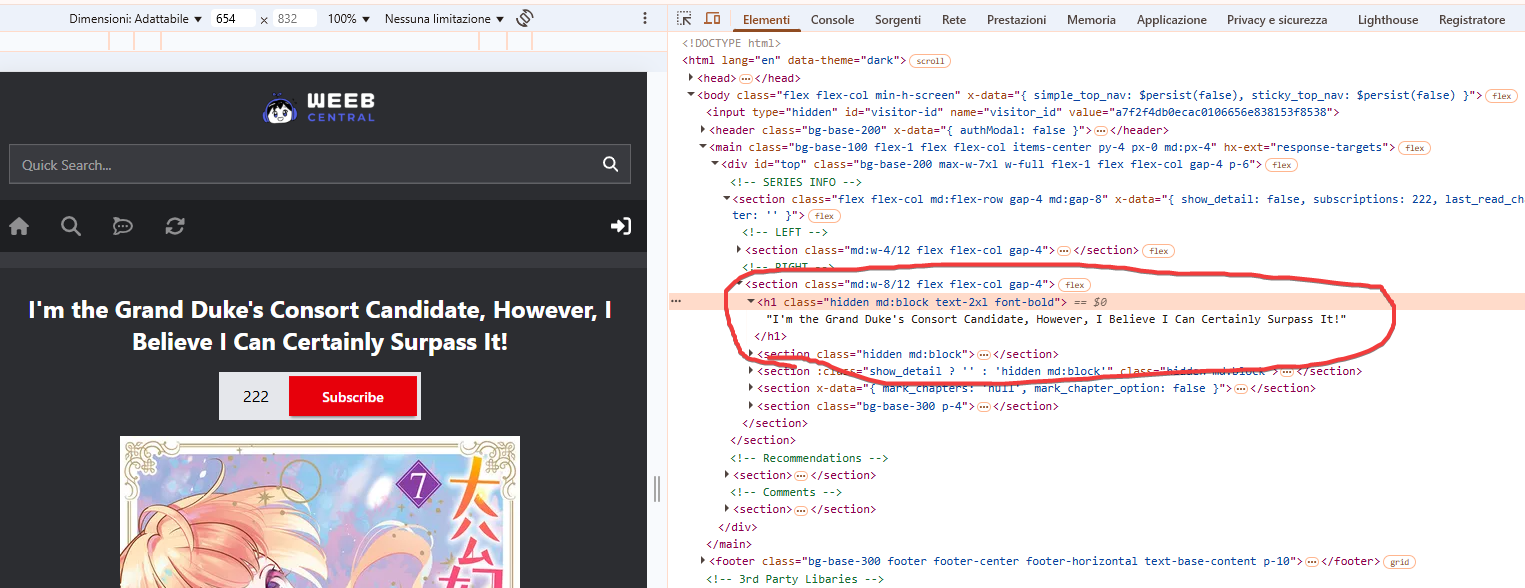
A questo punto sappiamo che il titolo del manga nella pagina si trova all'interno del primo tag “h1” presente nel codice. Ciò ci tornerà utile quando andremo a ricercarlo con lo script più avanti.
Trovato il titolo, adesso non ci resta da fare che capire come estrapolare la lista dei capitoli. Sempre dalla pagina in cui siamo (non serve uscire dalla modalità Sviluppatore) andiamo sulla lista capitoli nella pagina e clicchiamoci col destro sopra facendo sempre Ispeziona:
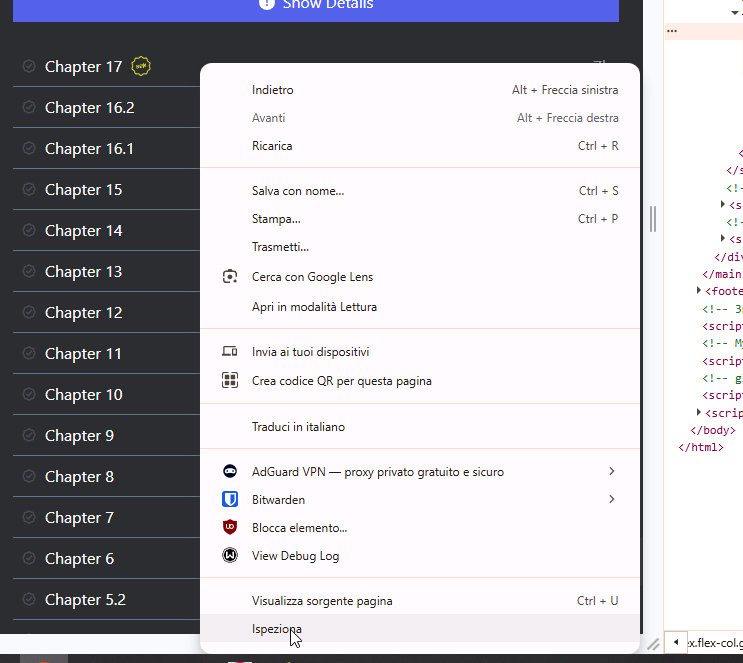
Verremo reindirizzata sul codice HTML in cui appare il capitolo che abbiamo ispezionato. Spostandoci con il mouse sopra il codice HTML verrà selezionata automaticamente la relativa parte sull'anteprima della pagina web, come visibile dall'immagine:
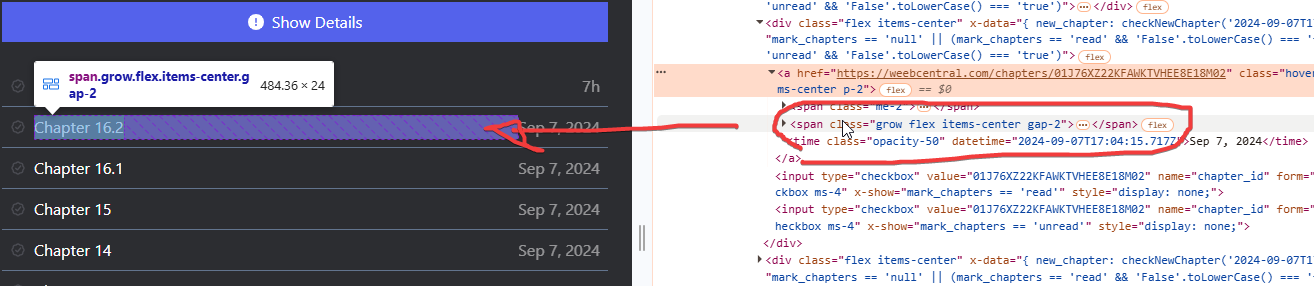
Qui però ci accorgiamo subito di una cosa: viene selezionato soltanto un capitolo, ossia quello che abbiamo ispezionato. A noi invece interessa tutta la lista capitoli, e quindi come fare per selezionarla tutta? Basta muoverci a ritroso (verso l'alto) sul codice HTML con il mouse e vedremo che pian piano verranno selezionate cose diverse all'interno dell'anteprima della pagina web. Non appena noteremo che tutta la lista capitoli viene selezionata sapremo che quello è il blocco che dovremo estrarre, nel nostro esempio qui sarà il “div” con id “chapters-list” come da immagine:
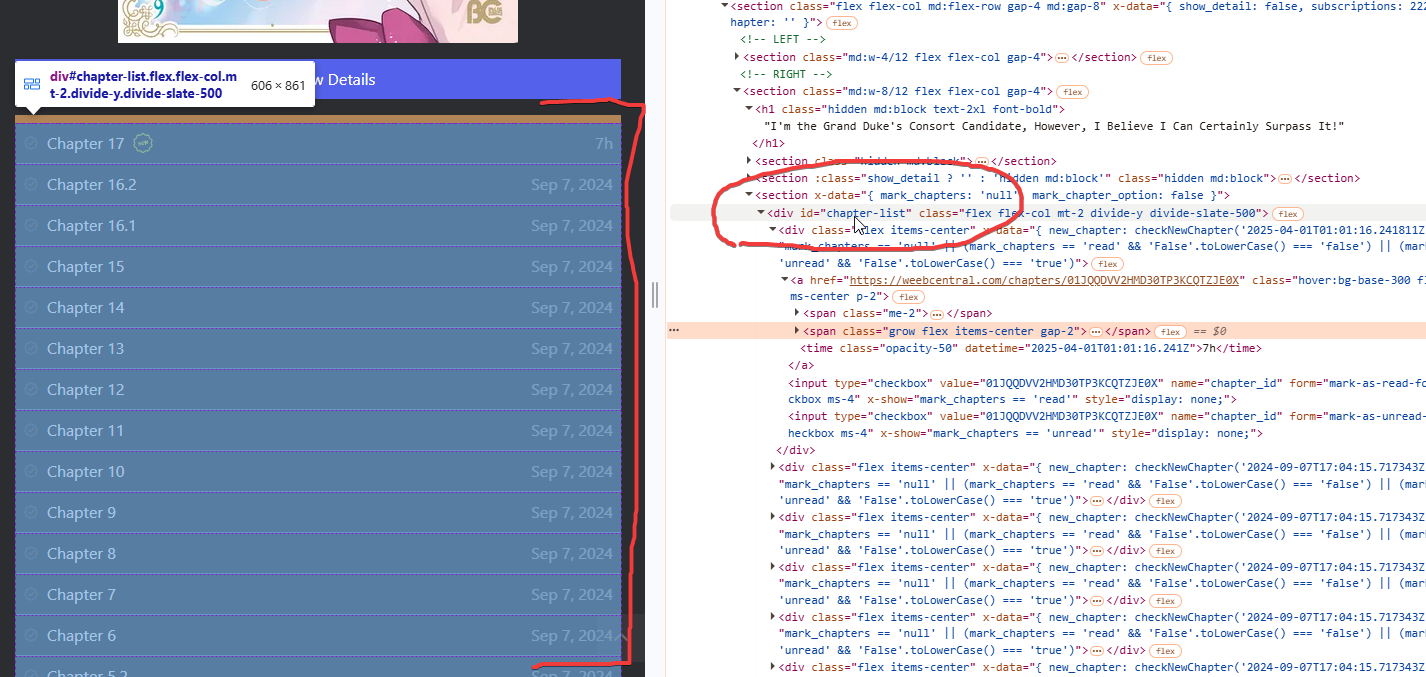
Una volta individuato il blocco dei capitoli da estrarre, dobbiamo andare a vedere come estrarre i singoli capitoli dalla lista. Niente di più semplice una volta individuato il blocco, perché ci basta notare i blocchi di codice HTML simili che si ripetono al suo interno:
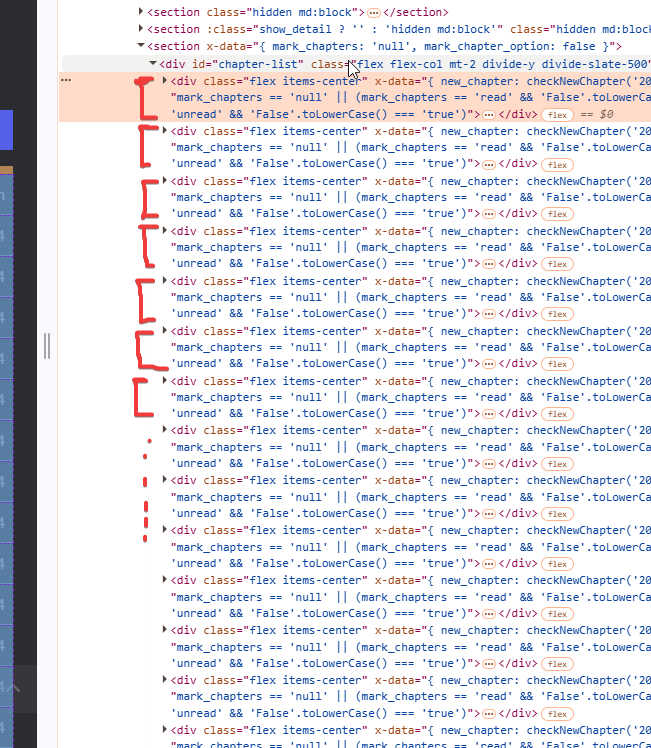
Ognuno di questi blocchi corrisponde al singolo capitolo della lista. Quindi adesso andiamo ad analizzare questi singoli blocchi per capire come estrapolare le info sul singolo capitolo (solitamente bastano solo titolo e URL, ma spesso sono presenti anche altri dati come gruppo di traduzione, uploader, data di rilascio, visualizzazioni, tutti dati che possono essere aggiunti se lo si vuole in quanto supportati da Manga Downloader.
Adesso quindi clicchiamo sulla freccetta a sinistra del blocco per “aprirlo” e analizzarne il contenuto:
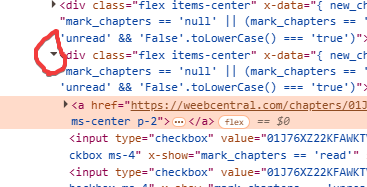
In questo caso ci rendiamo conto subito che ciò che ci interessa è tutto all'interno del blocco del tag “a” che troviamo al suo interno. Andando ad aprire anche quello sempre cliccando sulla freccetta scopriremo le varie parti che lo compongono:
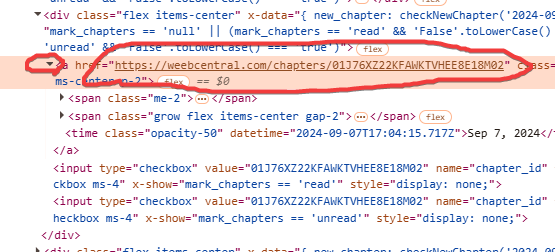
La prima cosa che ci risalta subito all'occhio è che l'URL del capitolo è proprio l'attributo “href” di questo tag “a”. Quindi una cosa l'abbiamo già trovata.
Per trovare il titolo e le altre info, spostiamoci col mouse sui vari blocchi contenuti all'interno e vediamo cosa viene selezionato sull'anteprima della pagina web. Nel nostro caso scopriremo che il titolo del capitolo è contenuto nel secondo tag “span”:
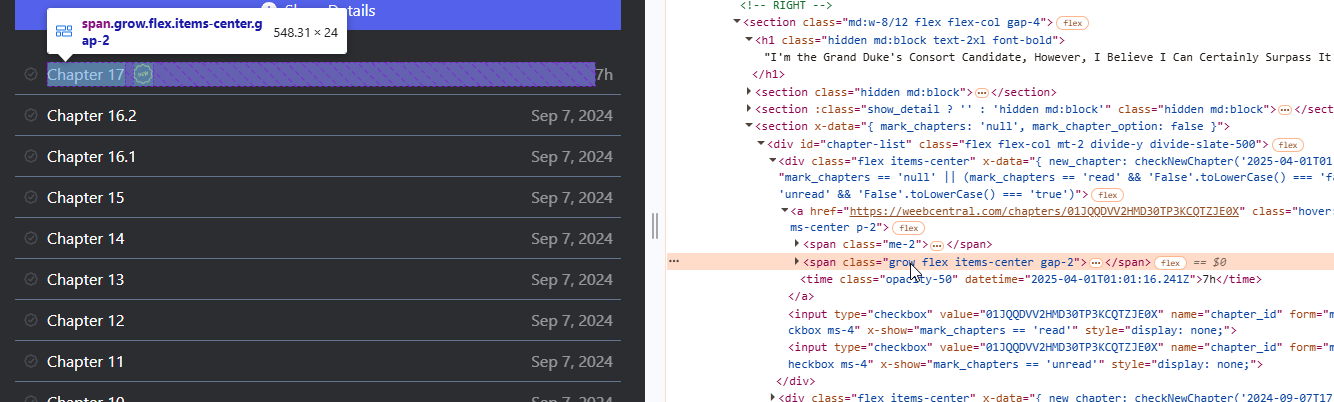
Mentre una informazione sulla data di rilascio del capitolo la possiamo trovare sul tag “time”:
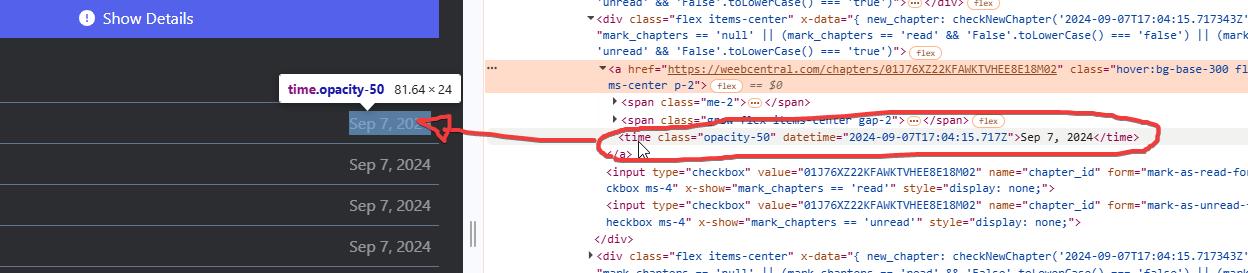
Queste, a vedere anche dall'anteprima della pagina web, sono le uniche informazioni che questo sito web mette a disposizione riguardo i singoli capitoli. Dunque possiamo fermarci qua, abbiamo tutto il necessario per estrarre i dati che ci interessano dalla pagina del manga, ossia titolo del manga, lista capitoli e per ogni capitolo il titolo, l'URL e la data di rilascio.
Adesso possiamo dunque passare a cercare di capire come estrarre la lista pagine da un capitolo. Per farlo dobbiamo aprire un qualsiasi capitolo dal sito e una volta caricate le pagine andare a vedere, usando il tasto Ispeziona su una qualsiasi della pagine, a livello di sorgente HTML dove vengono inserite:
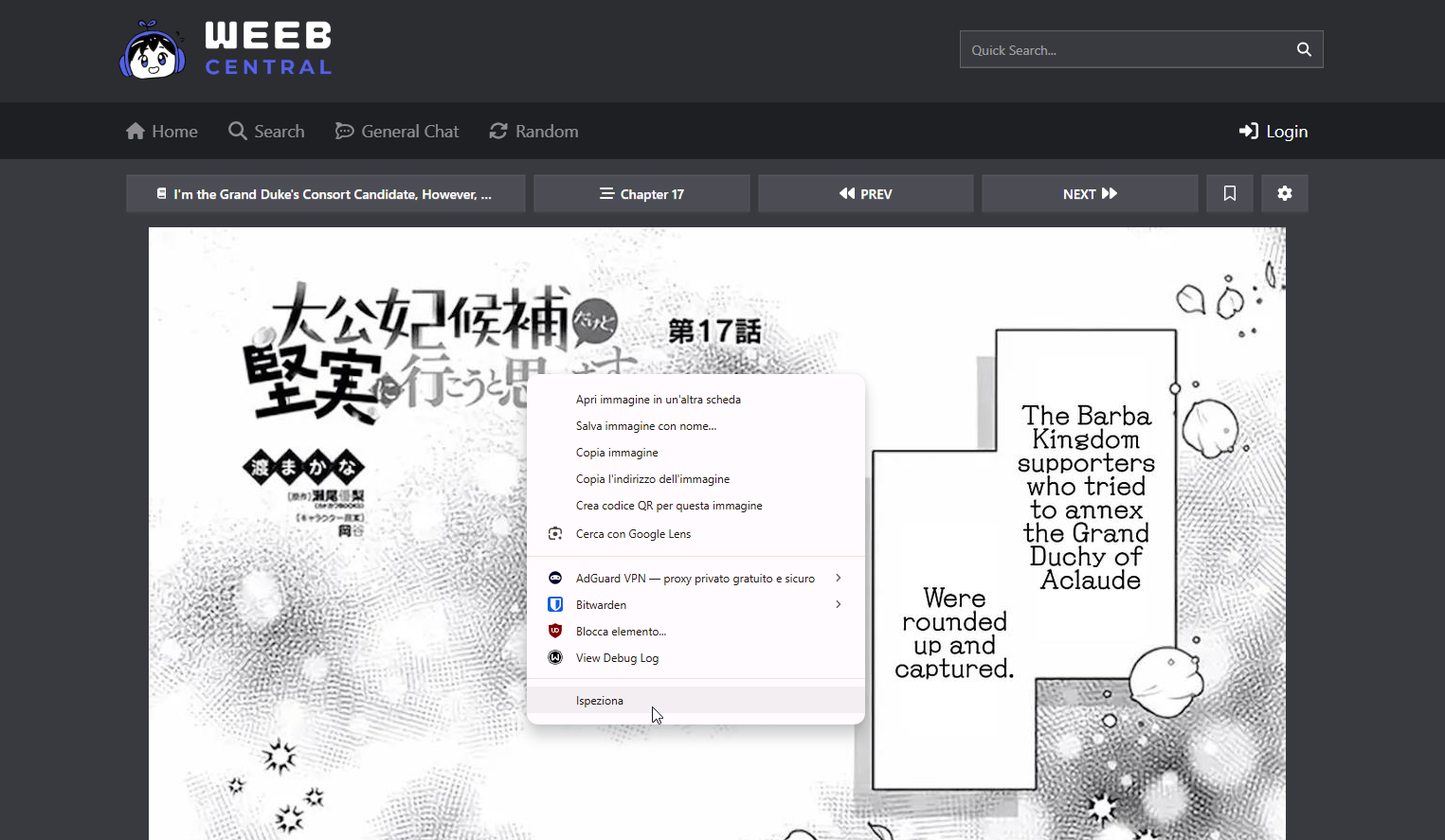
Si aprirà la solita schermta della modalità Sviluppatore che ormai dovreste conoscere bene e verrà visualizzato il corrispondente codice HTML della immagine su cui avete cliccato Ispeziona:
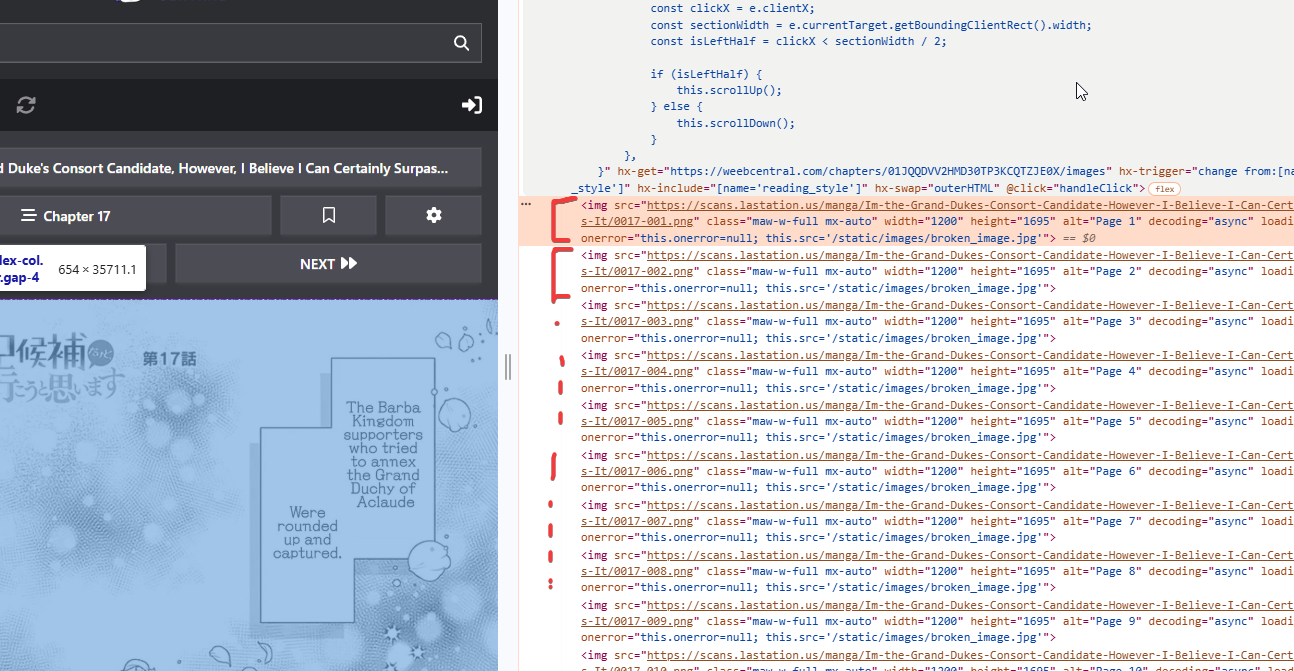
Come possiamo vedere siamo stati fortunati perché in questo caso sono semplicemente immagini presenti, una di seguito all'altra, all'interno di un tag “img” ciascuna. Quindi ci basterà estrarre l'attributo “src” di ciascun tag “img” presente e avremo i link diretti alle immagini!
Nota Importante: quello che vi ho mostrato è solo un esempio generico di come si analizza un sito web per cercare di estrapolarne le info che servono, purtroppo anche se il metodo è generale, ovviamente i tag specifici NON sono validi per tutti i siti web esistenti! Anzi, ogni sito web ha il suo codice HTML personale e quasi sicuramente diverso da tutti gli altri (a meno che non utilizzi dei framework generici), quindi dovrete purtroppo analizzare manualmente ogni sito web in maniera diversa. Vi avverto inoltre che a volte non è così facile capire come accedere ai contenuti perché i siti potrebbero offuscare il sorgente (renderlo insomma difficilmente leggibile da un umano) e in questo caso ci dovrete perdere ore a cercare di ricostruire come funziona. Allo stesso modo spesso i siti web usano Javascript per inserire del codice in maniera dinamica all'interno del codice sorgente HTML. Ciò farà sì che anche se voi lo vediate all'interno del browser web ispezionandolo, poi in realtà quei blocchi di codici non saranno presenti nel codice sorgente HTML che andrete a scaricare col vostro script! Ovviare a questo problema sarà ancora più complesso perché dovrete risalire al codice Javascript che utilizza il sito, analizzare e studiarvi quello, e poi ingegnarvi nel creare un metodo equivalente per accedere a quei contenuti (ad esempio usando un interprete esterno di Javascript magari, oppure caricandone il codice tramite browser web esterno come ad esempio usando tool appositi o librerie come Selenium o simili).
Insomma estrapolare informazioni da siti web, soprattutto quelli ufficiali ed avanzati, può essere un bel lavoro da fare e non sempre sarà banale. Ovviamente se avete le capacità tutto è possibile, ma per alcuni siti web vi assicuro che vi serviranno capacità ben al di sopra della media, quindi non date per scontato che possiate supportare facilmente qualsiasi sito web.
2) Creazione dello script
Una volta capito come estrapolare le informazioni che ci servono dal sito web che vogliamo supportare è ora di passare a creare gli script veri e propri che si occuperanno del lavoro.
Vi lascio di seguito 2 esempi in linguaggi di programmazione diversi (Java e Python) ma, lo ripeto di nuovo, nulla vi vieterebbe di usare altri linguaggi allo stesso identico modo.
Script usando JAVA
Come detto già sopra, lo script deve fare essenzialmente 3 cose, scaricare la pagina web, estrapolarne le informazioni dal codice HTML e stampare a schermo un oggetto JSON che possa essere poi interpretato da Manga Downloader. In JAVA tutto questo può essere fatto con 2 semplici librerie: jsoup e gson.
Eccovi dunque il codice sorgente, commentato passo per passo, di uno script JAVA che può aggiungere il supporto a weebcentral a Manga Downloader:
/* Importiamo le librerie necessarie: (ovviamente dovranno essere inserite fisicamente nel classpath!) */ import com.google.gson.JsonArray; import com.google.gson.JsonObject; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class Weebcentral { /** * Il main è la prima funzione che viene avviata quando lanciate lo script. */ public static void main(String[] args) { JsonObject output_json = new JsonObject(); // Creiamo l'oggetto JSON da restituire if (args.length != 2) { // Controlliamo che gli argomenti siano giusti, altrimenti diamo un messaggio di errore. output_json.addProperty("error", "Invalid arguments count."); } else { if (args[1].equalsIgnoreCase("CHAPTERS")) { // Se il secondo argomento è CHAPTERS allora avviamo la funzione per acquisire la lista capitoli GetChapters(args[0]); return; } else if (args[1].equalsIgnoreCase("PAGES")) { // Se il secondo argomento è PAGES allora avviamo la funzione per acquisire la lista pagine GetPages(args[0]); return; } else { // Se il secondo argomento è errato mostriamo un messaggio di errore output_json.addProperty("error", "Unknown second argument (it can be only CHAPTERS or PAGES)."); } } System.out.println(output_json.toString()); // Stampiamo a schermo eventuali messaggi di errore } /** * GetChapters prende come argomento l'URL di un manga e stampa a schermo le informazioni su titolo e lista capitoli */ private static void GetChapters(String u) { JsonObject output_json = new JsonObject(); // Creiamo l'oggetto JSON da stampare a schermo Document doc; try { doc = Jsoup.connect(u).timeout(10*1000).get(); // Ci connettiamo al sito web e ne acquisiamo il sorgente HTML Elements content = doc.getElementsByTag("h1"); // Estrapoliamo il primo elemento con tag "h1" if (content.isEmpty()) { output_json.addProperty("manga", "ERROR"); // Se il tag non viene trovato allora mostriamo un errore come titolo del manga } else { output_json.addProperty("manga", content.first().ownText().trim()); // Se il tag viene trovato aggiungiamo il titolo del manga all'oggetto JSON } JsonArray out_chapters = new JsonArray(); // Creiamo l'array JSON che conterrà i vari capitoli Element div = doc.getElementById("chapter-list"); // Estrapoliamo l'elemento con ID "chapter-list" Elements as = div.getElementsByTag("a"); // Esrapoliamo tutti gli elementi con tag "a" dall'elemento estratto in precedenza for (Element a : as) { // Per ogni elemento con tag "a" presente JsonObject out_chapter = new JsonObject(); // Creaiamo l'oggetto JSON che conterrà le info del singolo capitolo out_chapter.addProperty("title", a.select("span[class='']").text().trim()); // Estrapoliamo il titolo del capitolo e aggiungiamo all'oggetto JSON out_chapter.addProperty("url", a.attr("href")); // Estrapoliamo l'URL del capitolo e aggiungiamo all'oggetto JSON out_chapter.addProperty("date", a.getElementsByTag("time").attr("datetime").trim()); // Estrapoliamo la data di rilasciao del capitolo e aggiungiamo all'oggetto JSON out_chapter.addProperty("language", "English"); // Impostiamo manualmente il linguaggio del sito web e aggiungiamo all'oggetto JSON // Dato che non abbiamo informazioni a riguardo impostiamo manualmente gli ultimi campi mancanti ad una stringa vuota e li aggiungiamo all'oggetto JSON: out_chapter.addProperty("group", ""); out_chapter.addProperty("uploader", ""); out_chapter.addProperty("views", ""); out_chapters.add(out_chapter); // Infine aggiungiamo l'oggetto JSON appena riempito di informazioni all'array creato in precedenza } output_json.add("chapters", out_chapters); // Aggiungiamo l'array ormai riempito di capitoli all'oggetto JSON da stampare a schermo } catch (Exception e) { output_json.addProperty("error", "Error while getting chapters list (" + e.getMessage() + ")"); // In caso di eventuali errori aggiungiamo un messaggio di errore all'oggetto JSON da stampare a schermo } System.out.println(output_json.toString()); // Stampiamo a schermo l'oggetto JSON finale che Manga Downloader andrà a leggere } /** * GetPages prende come argomento l'URL di un capitolo (ottenuto dalla funzione GetChapters()) e stampa a schermo le informazioni su titolo e lista capitoli */ private static void GetPages(String u) { JsonObject output_json = new JsonObject(); // Creiamo l'oggetto JSON da stampare a schermo output_json.addProperty("user-agent", ""); // Dato che non ci serve impostiamo il campo user-agent a una stringa vuota output_json.add("cookies",new JsonArray()); // Dato che non ci servono cookie per accedere al sito web, impostiamo il campo cookie a un array JSON vuoto try { /* Scarichiamo il sorgente HTML dal sito web: Nota: in questo caso vado ad aggiungere all'URL del capitolo alcuni parametri che mi faranno mostrare tutte le pagine, visto che altrimenti il sito ne caricherebbe solo 1 di pagina alla volta. Ho scoperto questi parametri semplicemente navigando sul sito e controllando la barra dell'URL sul browser web, ovviamente non serve sempre ma è specifico per questo sito. */ Document doc = Jsoup.connect(u + "/images?is_prev=False&reading_style=long_strip").timeout(10*1000).get(); String link; JsonArray out_pages = new JsonArray(); // Creiamo l'array JSON che conterrà i vari link alle pagine Elements imgs = doc.getElementsByTag("img"); // Estrapoliamo gli elementi con tag "img" for (int i = 0; i < imgs.size(); i++) { // Per ogni elemento con tag "img" link = imgs.get(i).attr("src").trim(); // Estrapoliamo il link diretto al file dell'immagine out_pages.add(link); // Aggiungiamo il link appena estratto all'array delle pagine } output_json.add("pages", out_pages); // Aggiungiamo l'array con le pagine all'oggetto JSON finale da stampare a schermo } catch (Exception e) { output_json.addProperty("error", "Error while getting pages list (" + e.getMessage() + ")"); // In caso di eventuali errori aggiungiamo un messaggio di errore all'oggetto JSON da stampare a schermo } System.out.println(output_json.toString()); // Stampiamo a schermo l'oggetto JSON finale che Manga Downloader andrà a leggere } }
Script usando Python
Per darvi dimostrazione che non dovete per forza conoscere JAVA per creare degli script, vi lascio uno script scritto stavolta in Python e che fa esattamente le stesse medesime cose che faceva lo script JAVA che avete visto qui sopra (è inutile che ve lo commento di nuovo tanto si capiscono i passaggi equivalenti). Stavolta le librerie che userà Python sono requests per scaricare le pagine web, BeautifulSoup per analizzare il codice HTML e json per creare oggetti JSON.
import sys import requests import json from bs4 import BeautifulSoup def get_chapters(url): output_json = {} try: response = requests.get(url, timeout=10) response.raise_for_status() soup = BeautifulSoup(response.text, 'html.parser') title_element = soup.find('h1') if title_element: output_json["manga"] = title_element.text.strip() else: output_json["manga"] = "ERROR" chapters = [] chapter_list_div = soup.find(id="chapter-list") if chapter_list_div: for a in chapter_list_div.find_all('a'): chapter_info = { "title": a.find('span', class_='').text.strip(), "url": a.get('href'), "date": a.find('time').get('datetime').strip(), "language": "English", "group": "", "uploader": "", "views": "" } chapters.append(chapter_info) output_json["chapters"] = chapters except Exception as e: output_json["error"] = f"Error while getting chapters list ({str(e)})" print(json.dumps(output_json, indent=4)) def get_pages(url): output_json = { "user-agent": "", "cookies": [] } try: response = requests.get(f"{url}/images?is_prev=False&reading_style=long_strip", timeout=10) response.raise_for_status() soup = BeautifulSoup(response.text, 'html.parser') pages = [] for img in soup.find_all('img'): src = img.get('src').strip() pages.append(src) output_json["pages"] = pages except Exception as e: output_json["error"] = f"Error while getting pages list ({str(e)})" print(json.dumps(output_json, indent=4)) def main(): if len(sys.argv) != 3: print(json.dumps({"error": "Invalid arguments count."}, indent=4)) return url, mode = sys.argv[1], sys.argv[2].upper() if mode == "CHAPTERS": get_chapters(url) elif mode == "PAGES": get_pages(url) else: print(json.dumps({"error": "Unknown second argument (it can be only CHAPTERS or PAGES)."}, indent=4)) if __name__ == "__main__": main()
3) Configurazione di Manga Downloader
Adesso che avete creato il vostro script bisogna impostare Manga Downloader perché lo utilizzi correttamente. Siccome gli script in questi esempi non prevedono la creazione di un eseguibile (un EXE di sotto Windows per intenderci) dovremo creare manualmente dei lanciatori per lo script, nulla di complicato tranquilli. Creiamo un semplice file di testo TXT e al suo interno scriviamo il comando completo per lanciare lo script che abbiamo scelto a seconda di quale sistema operativo stiamo usando. Ad esempio per lanciare lo script JAVA su Windows basterà scrivere all'interno del file di testo:
@echo off java -jar script.jar %*
dove al posto di script.jar va inserito il nome che avrete dato al vostro script dopo la compilazione. La parte con “echo off” serve solo ad evitare che venga stampato altro sullo schermo oltre al codice di ritorno del programma (così da evitare che Manga Downloader non riesca a interpretare ciò che viene stampato in JSON corretto) mentre quella con “%*” serve a far sì che gli argomenti (URL e parola chiave) che Manga Downloader passa all'eseguibile quando lo richiama vengano a loro volta passati allo script che avete programmato voi.
Adesso se volete usare questo lanciatore sotto Windows rinominate il file di testo .txt con estensione .bat, così che diventi eseguibile e cambi icona come da immagine:

Se invece volete usarlo sotto Linux o Mac dovrete modificare il file di testo in questo modo:
#!/bin/bash java -jar script.jar "$@"
dove al posto di script.jar va inserito sempre il nome che avrete dato al vostro script.
Adesso dovrete rinominare questo file di testo in formato .sh e dargli i permessi di esecuzione dando da terminale il comando:
chmod +x script.sh
ovviamente col terminale dovrete essere già esservi spostati nella cartella dove si trova il lanciatore appena creato sennò non vi troverà il file.
Nota: se invece il vostro script fosse quello in Python ad esempio, allora al posto di:
@echo off java -jar script.jar %*
dovreste scrivere:
@echo off python script.py %*
in pratica a cambiare è solo il comando per lanciare lo script, ciò accade con ogni linguaggio che state usando ma penso che questo lo sappiate già.
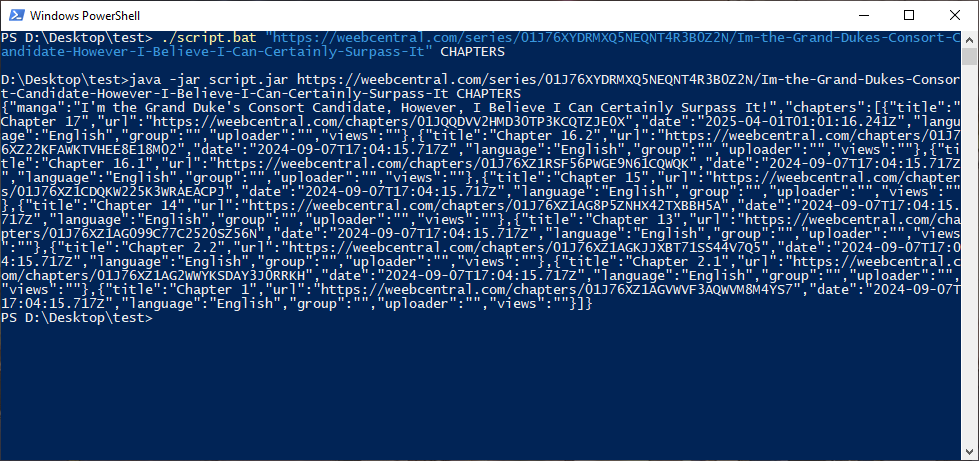
Creato l'eseguibile, assicuratevi che sia inserito all'interno della stessa cartella dove si trova lo script principale (in questo caso il file .jar). Per assicurarci che tutto funzioni correttamente, ancora prima di usarlo con Manga Downloader, possiamo provare ad avviare lo script da terminale dandogli come argomenti l'URL del manga che vogliamo scaricare e la parola chiave CHAPTERS, così da controllare che venga correttamente stampato a schermo l'elenco dei capitoli come da immagine:
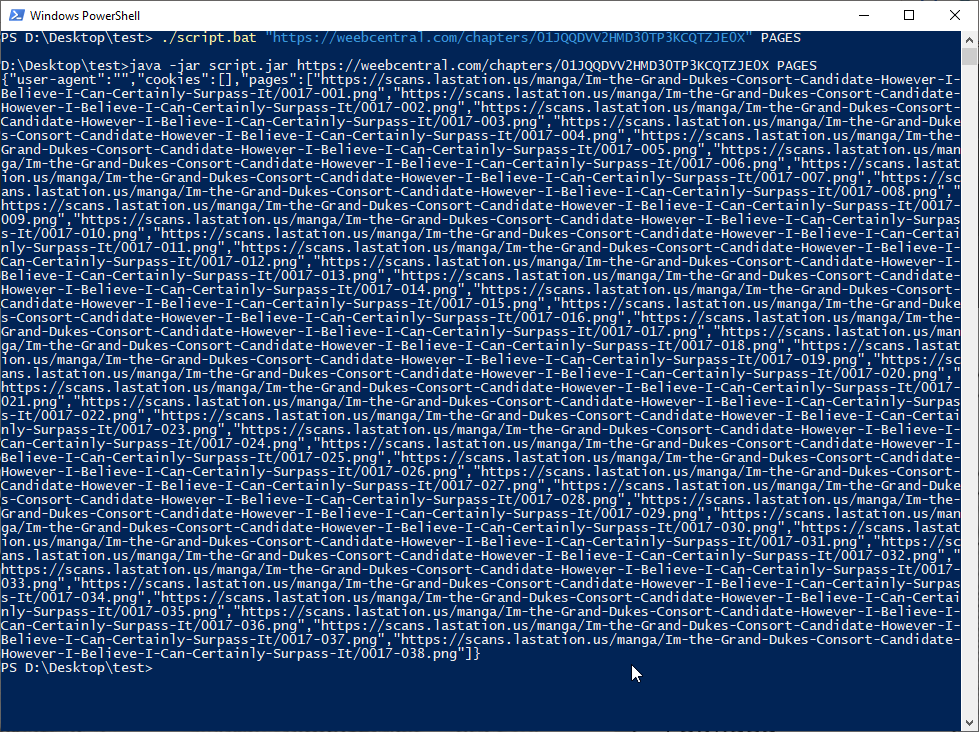
Volendo possiamo testare anche le pagine, semplicemente cambiando i parametri con l'URL di uno dei capitoli e la parola chiave PAGES:
Ora che siamo certi che il nostro script funziona correttamente, passiamo alla configurazione di Manga Downloader.
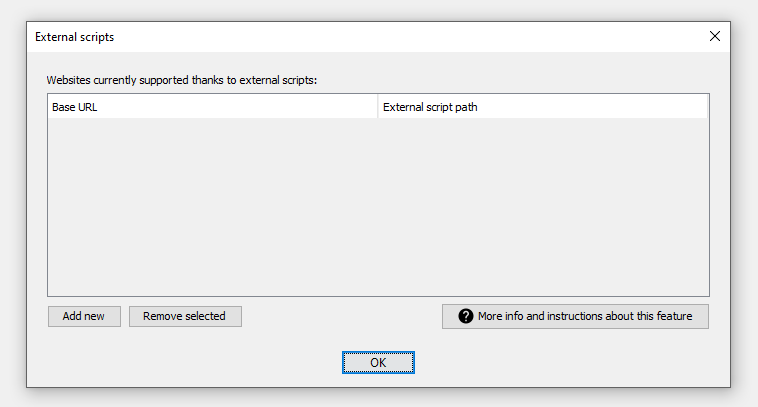
Avviate il programma e cliccate sul menù Modifica quindi scegliete la voce Script Esterni:
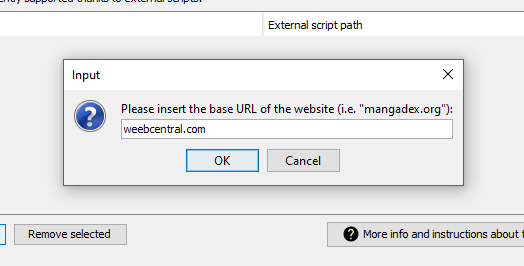
Nella schermata che apparirà cliccate sul pulsante Aggiungi e vi verrà chiesto di inserire il dominio del sito web che volete supportare col vostro script, nel nostro esempio dunque inseriremo weebcentral.com:
Adesso vi verrà chiesto di selezionare il file eseguibile del vostro script. Fate attenzione qui a selezionare il lanciatore (formato BAT o SH che avete creato prima) e non lo script direttamente. Una volta completato avrete qualcosa del genere:
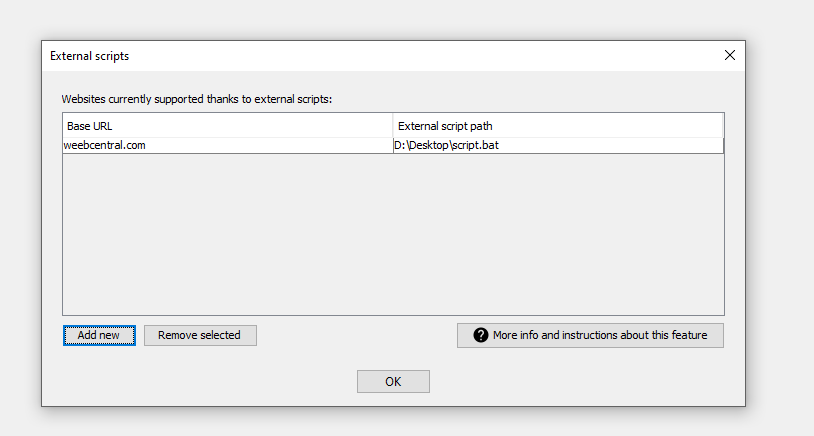
A questo date l'ok per salvare il tutto e siete pronti per utilizzare il vostro script!
Aprite la schermata di caricamento nuovo manga dal programma e inserite l'URL del manga che volete scaricare, facendo attenzione sotto di esso a selezionare la casella “Script esterno” come framework generico:
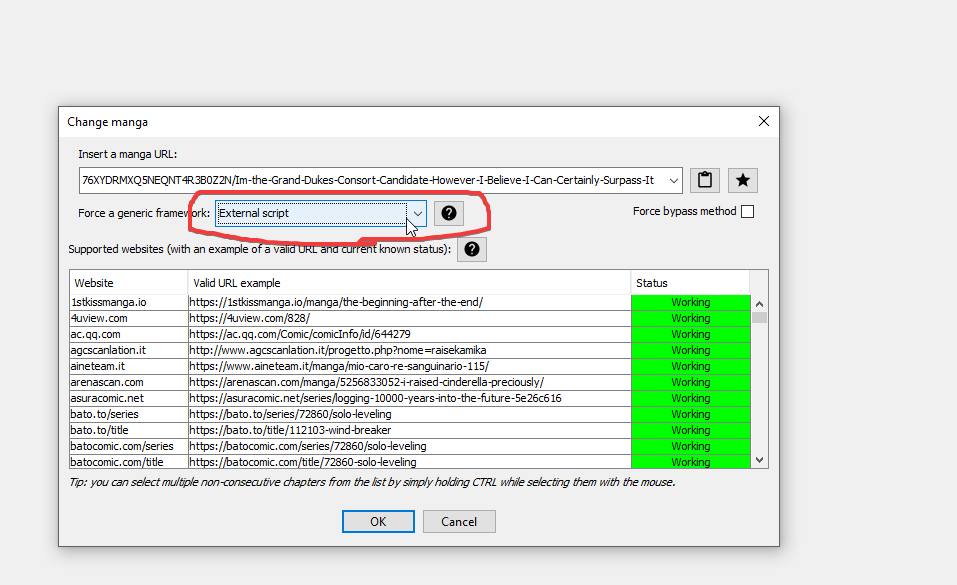
Date l'ok e se il vostro script è corretto Manga Downloader caricherà i dati dei capitoli all'interno del programma:
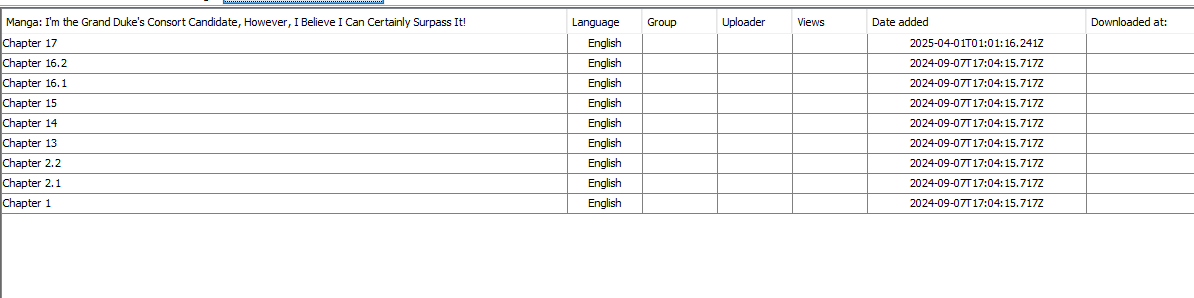
E vi permetterà di scaricare i capitoli senza errori:
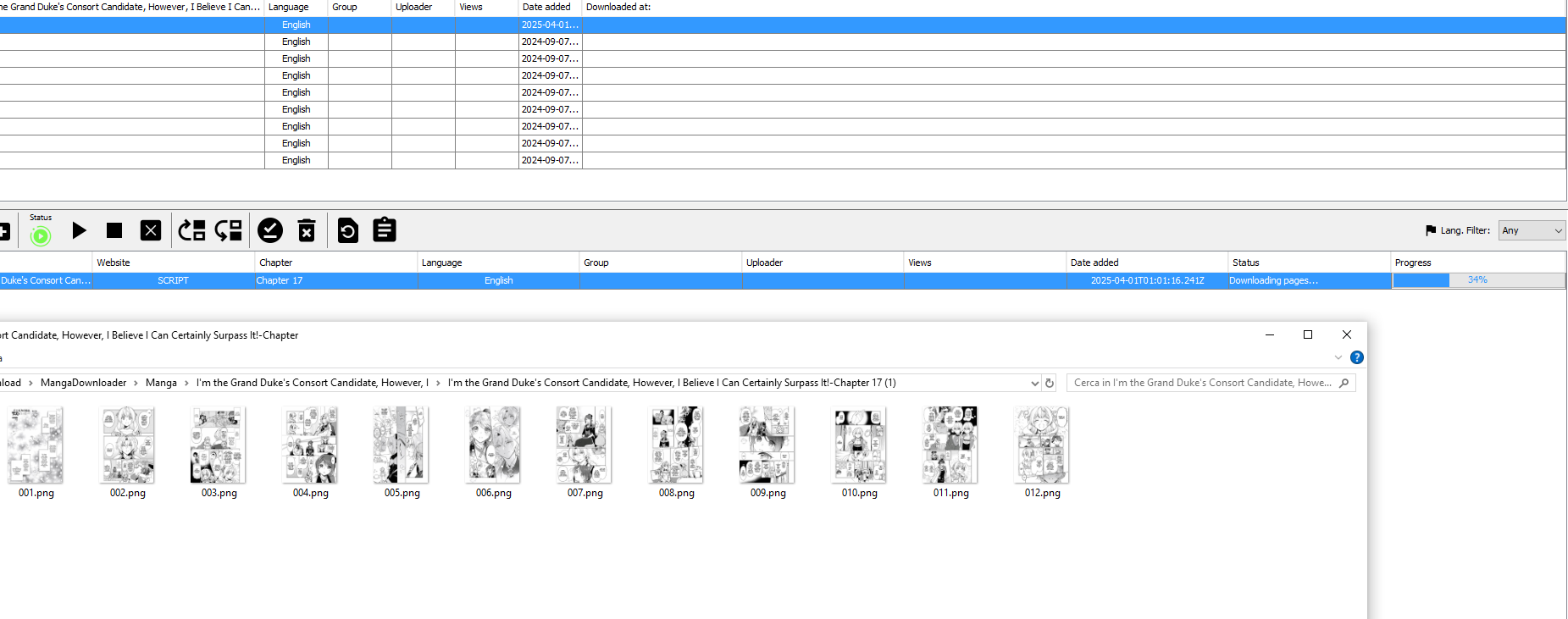
Ed abbiamo finito! Adesso potete usare lo script esterno per tutti i manga presenti su quel sito web e se in futuro dovesse cambiare il sito vi basterà aggiornare il vostro script senza nemmeno dover più attendere un aggiornamento ufficiale di Manga Downloader.